📌 DBMS는 무엇인가요?
- DBMS는 데이터베이스 관리 시스템을 나타냅니다. 사용자가 데이터에 관한 정보를 가능한 한 효율적이고 효과적으로 구성, 복원 및 검색 할 수 있도록하는 응용 프로그램 모음입니다. 널리 사용되는 DBMS 중 일부는 MySql, Oracle 등입니다.
📌 데이터베이스 종류 별로 설명해 주세요
- 데이터를 보존하는 형식에 따라 나뉩니다.
- 계층형 데이터 베이스는 데이터를 폴더와 파일 등 계층 구조로 데이터를 저장하는 방식입니다. 하드디스크가 예시로 있고, 최초로 등록된 데이터베이스 타입입니다.
- 관계형 데이터베이스는 데이터를 2차원의 표 형식으로 관리하는 데이터베이스입니다. 데이터를 column과 row로 구성된 하나 이상의 테이블로 나타내며, primary key가 각 row를 식별할 수 있습니다. 예시로는 Oracle, MySQL등이 있습니다. (row : 레코드 혹은 튜플, column : 속성)
- 객체지향 데이터베이스는 객체 그대로를 데이터베이스의 데이터로 저장하는 것입니다. 사용자 정의 데이터 혹은 멀티미디어 데이터 등 복잡한 데이터 구조를 표현하고 관리할 수 있습니다. 예시로 ONTOS, GemStone등이 있습니다.
- KVS(키-밸류 스토어)는 키와 그에 대응하는 value 형태로 데이터를 저장하는 데이터베이스입니다. NoSQL(Not only SQL)이라는 슬로건으로 생겨난 데이터 베이스로, 열 지향 데이터 베이스라고도 불립니다. 관계형 데이터베이스보다 처리 속도를 높이고 비정형 데이터를 보다 쉽게 저장할 수 있다는 장점이 있습니다.
📌 데이터베이스의 특징에 대해 설명해주세요.
- 실시간 접근성(Real-Time Accessibility) : 비정형적인 질의(조회)에 대하여 실시간 처리에 의한 응답이 가능해야 하며
-지속적인 변화(Continuous Evloution) : 데이터베이스의 상태는 동적입니다. 즉 새로운 데이터의 삽입(Insert), 삭제(Delete), 갱신(Update)으로 항상 최신의 데이터를 유지해야 합니다.
- 동시 공용(Concurrent Sharing) : 데이터베이스는 서로 다른 목적을 가진 여러 응용자들을 위한 것이므로 다수의 사용자가 동시에 같은 내용의 데이터를 이용할 수 있어야 합니다.
- 내용에 의한 참조(Content Reference) : 데이터베이스에 있는 데이터를 참조할 때 데이터 레코드의 주소나 위치에 의해서가 아니라 사용자가 요구하는 데이터 내용으로 찾습니다.
📌 RDBMS와 NoSQL의 차이에 대해 설명해주세요.

RDBMS는 모든 데이터를 2차원 테이블 형태로 표현합니다.
- 장점 : 스키마에 맞춰 데이터를 관리하기 때문에 데이터의 정합성을 보장할 수 있다.
- 단점 : 시스템이 커질 수록 쿼리가 복잡해지고 성능이 저하되며 Scale-out이 어렵다(Scale-up만 가능)
NoSQL(Not Only SQL)은 데이터간의 관계를 정의하지 않고, 스키마가 없어 좀 더 자유롭게 데이터를 관리할 수 있으며, 컬렉션이라는 형태로 데이터를 관리합니다.
- 장점 : 스키마 없이 Key-Value 형태로 데이터를 관리해 자유롭게 데이터를 관리할 수 있다.
- 데이터 분산이 용이하여 성능 향상을 위한 scale-up 뿐만아닌 scale-out 또한 가능하다.
- 단점 : 데이터 중복이 발생할 수 있고, 중복된 데이터가 변경될 경우 수정을 모든 컬렉션에서 수행해야 한다.
- 스키마가 존재하지 않기에 명확한 데이터 구조를 보장하지 않아 데이터 구조 결정이 어려울 수 있다.
💡 그렇다면 RDBMS와 NoSQL은 어느 경우에 적합한가요?
RDBMS는 데이터 구조가 명확하고, 변경 될 여지가 없으며 스키마가 중요한 경우 사용하는 것이 좋습니다. 또한 중복된 데이터가 없어(데이터 무결성) 변경이 용이하기 때문에 관계를 맺고 있는 데이터가 자주 변경이 이루어지는 시스템에 적합합니다.
NoSQL은 정확한 데이터 구조를 알 수 없고 데이터가 변경/확장 될 수 있는 경우 사용하는 것이 좋습니다. 또한 단점에서도 명확하듯 데이터 중복이 발생할 수 있으며 중복된 데이터가 변경될 시 모든 컬렉션에서 수정해야 하기 때문에 Update가 많이 이루어지지 않는 시스템에 좋으며, Scale-out이 가능하다는 장점을 활용해 막대한 데이터를 저장해야 해서 DB를 Scale-out 해야 되는 시스템에 적합합니다.
Q) NoSQL이 기존 RDBMS와 다른 점은?
답변 : NoSQL 은 스키마가 없습니다. 즉 데이터 관계와 정해진 규격(table-column의 정의)이 없습니다.
관계 정의가 없으니 Join이 불가능하고 (하지만 reference와 같은 기능으로 비슷하게 구현은 가능) 트랜잭션을 지원하지 않습니다.
분산처리(수평적 확장)의 기능을 쉽게 제공한다는 장점이 있습니다. 대부분의 NoSQL DB는 분산처리기능을 목적으로 나왔기 때문에 분산처리 기능을 자체 프레임워크에 포함하고 있습니다.
📌 데이터베이스에서 다양한 유형의 관계는 무엇입니까?
- 관계란 두 엔티티가 서로 관련이 있을 때를 말하며, 1:1, 1:N, N:M 관계를 맺을 수 있습니다.
- 1 : 1 관계는 한 엔티티가 상대 엔티티와 반드시 단 하나의 관계를 가지는 것을 의미합니다.
- 1: N 관계는 하나의 레코드가 서로 다른 여러 개의 레코드와 연결된 경우를 의미합니다.
- N : M 관계는 여러 개의 레코드가 다른 테이블의 여러 개의 레코드와 관계가 있는 경우입니다. N:M(다대다) 관계를 위해 스키마를 디자인할 때에는, Join 테이블을 만들어 관리합니다. 1:N(일대다) 관계와 비슷하지만, 양방향에서 다수의 레코드를 가질 수 있습니다.
📌 DBMS의 장단점에 대해 설명해주세요.
1. 장점
- 데이터 중복 및 불일치를 최소화 할 수 있습니다.
- 데이터를 표준화할 수 있고 데이터의 보안을 향상시킬 수 있습니다.
- 데이터의 일관성 및 무결성을 유지할 수 있습니다.
- 다양한 유형의 장애로부터 복구를 할 수 있습니다.
- 동시 접근이 가능합니다.
- 여러 사용자 인터페이스를 제공합니다.
2. 단점
- 높은 비용 및 고급 인력이 필요합니다.
- 백업 및 복구 과정이 복잡합니다.
- DBMS는 통합된 시스템이기 때문에 그 일부의 고장이 전체 시스템을 정지시켜 시스템 신뢰성과 가용성을 저해할 수 있습니다.
3. 일관성 및 무결성을 유지한다는 것이 어떤 의미인가요?
데이터베이스 무결성이란?
답변 : 데이터 베이스에 저장된 데이터 값과 그것이 표현하는 현실 세계의 실제값이 일치하는 정확성을 말합니다.
개체 무결성 은 릴레이션에서 기본키를 구성하는 속성은 NULL값이나 중복값을 가질 수 없다.
참조 무결성 은 외래키 값은 NULL이거나 참조 테이블의 기본키 값이어야함
📌 DB 복구 모델 유형에 대해 설명해주세요
- 엔티티(Entity): 사람, 장소, 사물, 사건 등과 같이 독립적으로 존재하면서 고유하게 식별이 가능한 실세계의 객체를 의미합니다. (ex) 과목 코드가 F035 인 자료구조 등.
- 엔티티 집합(Entity Set): 동일한 속성을 가진 엔티티들의 집합을 의미합니다.
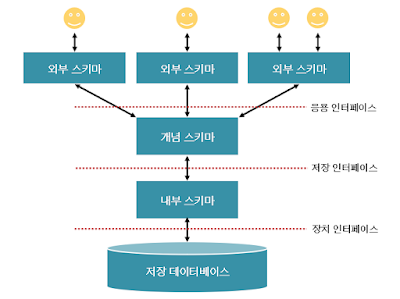
- 스키마 : 데이터 베이스의 구조를 전반적으로 기술한 것입니다. 구체적으로는 데이터베이스를 구성하는 데이터 개체(Entity), 속성(Attribute), 관계(Relationship) 등을 정의합니다. 사용자의 관점에 따라 외부 스키마, 개념 스키마, 내부 스키마로 구분하며, DBMS는 외부 스키마에 명세된 사용자의 요구를 개념 스키마 형태로 변환하고, 이를 다시 내부 스키마 형태로 반환합니다.
1) 외부 스키마(사용자 뷰) : 사용자의 입장에서 정의한 데이터 베이스의 논리적 구조를 의미합니다. 데이터들을 어떤 형식, 구조, 화면을 통해 사용자에게 보여줄 것인가에 대한 명세를 말하며 하나의 데이터베이스에는 여러개의 외부 스키마가 있을 수 있다. 일반 사용자는 SQL을 이용하여 DB를 쉽게 사용할 수 있다. 응용 프로그래머는 C, 자바 등의 언어를 사용하여 DB에 접근한다.
2) 개념 스키마(전체적인 뷰): 데이터베이스의 전체적인 논리적 구조를 의미합니다. 모든 이용자가 필요로 하는 데이터를 총합한 조직 전체의 데이터 베이스로, 개체 간의 관계와 제약조건, 데이터 베이스의 접근 권한, 보안 등에 관한 명세를 나타냅니다.
3) 내부 스키마: 물리적 저장장치의 입장에서 본 데이터베이스 구조를 의미합니다. 실제로 데이터베이스에 저장될 레코드의 물리적인 구조, 저장 데이터 항목의 표현 방법, 내부 레코드의 물리적 순서 등을 나타냅니다.
📌 데이터베이스 언어(DDL, DML, DCL)에 대해 설명해주세요
- DDL (정의어 : Data Definition Language) : 데이터베이스 구조를 정의, 수정, 삭제하는 언어 ( alter, create, drop)
- DML (조작어 : Data Manipulation Language) : 데이터베이스내의 자료 검색, 삽입, 갱신, 삭제를 위한 언어 ( select, insert, update, delete)
- DCL (제어어 : Data Control Language) : 데이터에 대해 무결성 유지, 병행 수행 제어, 보호와 관리를 위한 언어 ( commit, rollback, grant, revoke )
📌 쿼리의 수행 순서를 알려주세요.

FROM, JOIN > WHERE, GROUP BY, HAVING > SELECT > ORDER BY > DISTINCT > LIMIT
1. FROM과 JOIN
- JOIN이 먼저 실행되어 데이터가 SET으로 모아지게 된다. 서브쿼리도 함께 포함되어 임시 테이블을 만들 수 있게 도와준다.
2. WHERE
- 데이터셋을 형성하게 되면 WHERE의 조건이 개별 행에 적용된다. WHERE절의 제약 조건은 FROM절로 가져온 테이블에 적용될 수 있다.
3. GROUP BY
- WHERE의 조건 적용 후 나머지 행은 GROUP BY절에 지정된 열의 공통 값을 기준으로 그룹화된다. 쿼리에 집계 기능이 있는 경우에만 이 기능을 사용해야 한다.
4. HAVING
- GROUP BY절이 쿼리에 있을 경우 HAVING 절의 제약조건이 그룹화된 행에 적용된다.
5. SELECT
- SELECT에 표현된 식이 마지막으로 적용된다.
6. DISTINCT
- 표현된 행에서 중복된 행은 삭제
7.ORDER BY
- 지정된 데이터를 기준으로 오름차순, 내림차순 지정
8. LIMIT
- LIMIT에서 벗어나는 행들은 제외되어 출력된다.
📌 키의 종류에 대해 설명해주세요
1) 식별자(Identifier)
- 한 실체(Entity)내에서 각각의 인스턴스를 유일하게 구분할 수 있는 단일 속성 또는 그룹 속성
- 한 Entity 내에서 식별자에 동일한 값이 주복될 수 없으며, 이를 무결성이라고 합니다.
- 모든 Entity는 하나 이상의 식별자를 보유해야 하며, 여러 개의 식별자를 보유하는 경우도 있습니다.
2) 후보키(Candidate Key)
- Entity내에서 각각의 인스턴스를 유일하게 구분할 수 있는 속성
- 하나 또는 여러 개의 속성으로 구성
3) 기본키(Primary Key)
- Entity에서 각 인스턴스를 유일하게 식별하는데 가장 적합한 키. 후보키 중 선택한 하나의 속성
- 후보키 중 기본키를 선정할 때 고려해야 할 사항
- 해당 실체를 대표할 수 있을 것
- 업무적으로 활용도가 높을 것
- 길이가 짧을 것
- 기본키의 속성
- Not Null
- No Duplicate
- 유일(Unique)한 클러스터드 인덱스(Clustered Index)
4) 대체키(Alternate key)
- 후보키 중에 기본키로 선정되지 않은 속성
5) 복합키(Composite Key)
- 하나의 속성으로는 기본키가 될 수 없는 경우, 둘 이상의 컬럼을 묶어 식별자로 정의해야 하는데, 이를 복합키라 함
- 이슈 : 복합키 중 어떤 컬럼을 먼저 둘 것인가
- 이유 : 컬럼을 기본키로 정의하게 되면 기본적으로 해당 컬럼에 유니크한 클러스터드 인덱스가 정의되어지며, 이럴 경우 먼저 정의한 컬럼을 기준으로 인덱스가 생성되기 때문에 복합키 중에서 주로 조회의 조건으로 사용되는 컬럼을 먼저 정의하는 것이 성능 향상을 위해 도움이 된다.
6) 대리키(Surrogate Key)
- 식별자가 너무 길거나 여러개의 속성으로 구성되어 있는 경우, 인위적으로 추가하는 식별자로 인공키라고도 부른다.
- 한 Entity에서 식별자가 여러 속성으로 구성된 경우는 데이터를 수정하거나 검색하는데 수행속도가 떨어진다. 이럴 경우 사용할 수 있다.
Q ) Unique Key
- Unique 키는 유일성을 가지기 위해 설정해 놓은 키로 중복이 되는 것을 방지합니다. Primary 키는 오직 하나만 생성할 수 있지만, Unique키는 여러개 생성이 가능합니다. Primary키의 경우 NULL 값을 허용하지 않지만, Unique 키는 NULL 값을 허용합니다.
📌 SQL문의 처리 과정을 설명해주세요.
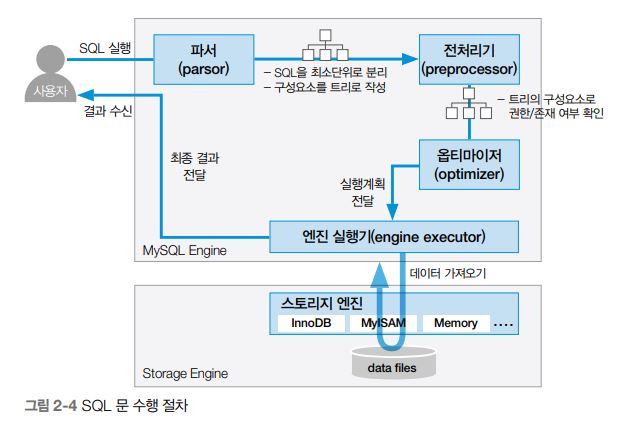
1) 파서(Parser)
- 쿼리 문장에서 문법(Syntax)오류를 확인 하고 문장을 분할하여 파서 트리를 만듭니다.
- 트리의 최소 단위는 >, <, = 등의 기호나 SQL 키워드로 분리합니다.
2) 전처리기
- 파서에서 생성한 트리를 토대로 SQL 문에 구조적인 문제가 없는지 파악합니다
- SQL 문에 작성된 테이블, 열, 함수, 뷰와 같은 오브젝트가 실질적으로 이미 생성된 오브젝트인지, 접근 권한은 부여되어 있는지 확인하는 역할
3) 옵티마이저(Optimizer)
- 요청받은 쿼리를 어떻게하면 가장 적은 비용으로 빠르게 즉, 최적으로 처리할지를 결정합니다.
- 단, 실행 계획을 수립하는 작업 자체만으로도 대기 시간과 하드웨어 리소스를 점유하므로, 시간과 리소스에 제한을 두고 실행 계획을 선정해야 합니다.
만약 실행 계획으로 도출할 수 있는 경우의 수가 지나치게 많을 때는 각각의 비용 산정 및 최적의 실행 계획을 선택하기까지 시간이 오래 걸리므로 모든 실행 계획을 판단하지는 않습니다. 따라서 옵티마이저가 선택한 최적의 실행 계획이 항상 최상의 실행 계획이 아닐 가능성도 있습니다.
4) 실행 엔진
- 옵티마이저에 의해 결정된 실행 계획대로 핸들러에게 지시합니다. (임시테이블 만들어라 → where 조건대로 레코드 읽어와라 → 읽은 레코드를 임시 테이블에 써라 → ...)
5) 핸들러(스토리지 엔진)
- MySQL 서버 가장 밑단에서 MySQL 실행 엔진의 요청에 따라 데이터를 디스크로 저장하고 디스크로부터 읽어 오는 역할
핸들러는 결국 스토지지 엔진을 의미하며 , InnoDB 테이블을 조작하는 경우에는 핸들러가 InnoDB 스토리지 엔진이 됨
실행 엔진이 내려준 지시대로 작업을 수행합니다.
📌 트리거(Trigger)에 대해 설명해주세요
- 트리거는 특정 테이블에 대한 이벤트에 반응해 INSERT, DELETE, UPDATE 같은 DML 문이 수행되었을 때, 데이터베이스에서 자동으로 동작하도록 작성된 프로그램입니다.
- 사용자가 직접 호출하는 것이 아닌, 데이터베이스에서 자동적으로 호출한다는 것이 가장 큰 특징입니다.
- 트리거를 사용하는 이유
- 업무 규칙을 보장
- 업무 처리 자동화
- 데이터 무결성 강화(변경, 생성, 제거, 복구 시)
📌 Index에 대해 설명해주시고, 장단점에 대해 말해주세요.
- Index는 데이터의 검색 속도를 높이는 기능입니다. 테이블을 처음부터 끝까지 검색하는 방법인 FTS(Full Table Scan)과는 달리 인덱스를 검색하여 해당 자료의 테이블을 엑세스 할 수 있습니다.
ex) DB를 책으로 비유하면 데이터는 책의 내용일 것이고, 데이터가 저장된 레코드의 주소는 index 목록에 있는 페이지 번호
- 장점 : 인덱스는 항상 정렬된 상태를 유지하기 때문에 원하는 값을 검색하는데 빠흡니다.
- 단점 : 인덱스를 구성하는 비용. 추가, 수정, 삭제 연산시에 인덱스를 형성하기 위한 추가적인 연산이 수행됩니다. 예를 들어, 새로운 값을 추가하거나 삭제, 수정하는 경우에는 쿼리문 실행 속도가 느려집니다. 데이터가 적다면 유지/관리 부담이 더 클 수 있으며 물리적인 공간을 차지합니다.
📌 Index의 자료구조 및 관리 방법을 알려주세요.
B+Tree 인덱스 자료구조
- 자식 노드가 2개 이상인 B-Tree를 개선시킨 자료구조이며, BTree 리프노드들을 LinkedList로 연결하여 순차 검색을 용이하게 합니다. 해시 테이블보다 나쁜 O(log2N)의 시간복잡도를 갖지만 일반적으로 사용되는 자료구조입니다.
해시 테이블
컬럼의 값으로 생성된 해시를 기반으로 인덱스를 구현합니다. 시간복잡도가 O(1)이라 검색이 매우 빠릅니다.
부등호(<,>)와 같은 연속적인 데이터를 위한 순차 검색은 불가능하기 때문에 사용에 적합하지 않습니다.
📌 클러스터 인덱스와 넌클러스터 인덱스의 차이점에 대해 알려주세요. (인덱싱에 따른 테이블 구조의 3가지 형태에 대해 말씀해주세요)
1. 힙(HEAP): 인덱싱되지 않은 테이블
특성
- 인덱싱되지 않은 상태
- 정렬의 기준이 없음. 데이터 페이지 내의 행들 간에 순서가 없음
- 클러스터형 인덱스가 없는 테이블
장단점
- INSERT에 유리(순서없이 그냥 페이지 빈 곳에 새 데이터를 추가하기만 하면 됨)
- SELECT에 불리(원하는 데이터를 찾기 위해서는 모든 데이터를 스캔해보아야 함. (Table Scan))
2. 클러스터형 인덱스
특성
- 인덱스된 컬럼을 기준으로 데이터가 물리적으로 정렬된다.
- 물리적으로 테이블의 row를 정렬하는 것이 필수적이라서 결과적으로는 클러스터된 인덱스는 로우의 모든 컬럼을 포함한다.
- 테이블에서 단 하나의 클러스터드 인덱스만 존재할 수 있고, 모든 로우는 클러스터 인덱스에 명시된 순서대로 정렬된다.
- 클러스터드 인덱스가 없는 테이블에서는 데이터가 위에 설명한대로 정렬되지 않은 힙으로 저장된다. 힙은 정렬된 구조를 갖지 않는다. 테이블의 사이즈가 증가할수록 이러한 구조는 많은 문제를 발생시킬 수 있다.
모든 컬럼을 읽을 필요가 있는 읽기 전용 프로그램을 구성한다면, 클러스터형 인덱스는 좋은 선택이 될 수 있다.
- 클러스터드 인덱스는 트리로 저장된다. 클러스터 인덱스를 설정하면, 실제 데이터는 Leaf Node에 저장된다. 이러한 구성은 인덱스에 대한 look-up이 수행됐을 때 속도를 빠르게 해준다. 결과적으로, 낮은 숫자의 IO 연산이 요구된다.
- 추가적으로 인덱스는 데이터를 새로운 테이블에 옮기지 않고도 재구성이 가능하다.
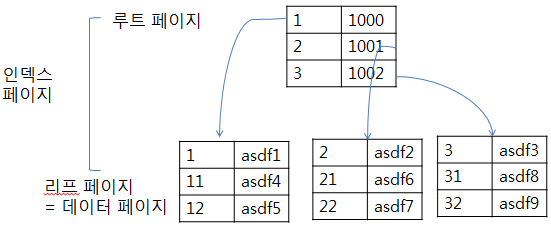
3. 논클러스터형 인덱스
- B-tree 인덱스라고도 불린다.
- 논클러스터드 인덱스 내부에서 논리적인 방법으로 데이터가 정렬된다. 로우는 논클러스터드 인덱스의 열과 다른 순서로 물리적으로 저장될 수 있다. 따라서 인덱스가 생성되고, 인덱스의 데이터가 인덱스 컬럼에 따라 논리적으로 정렬된다.
- 논클러스터드 인덱스는 실제 데이터의 상단에 생성된다.
- 테이블에는 여러 개의 논클러스터드 인덱스가 있을 수 있다.
- 클러스터드 인덱스와 다르게, 논클러스터드 인덱스의 리프 페이지들이 실제 데이터를 포함하지 않는다. 논클러스터드 인덱스의 리프 페이지는 포인터를 가지고 있다
- 포인터들은 책 목차 부분에 있는 페이지 숫자들과 같은 역할을 한다.
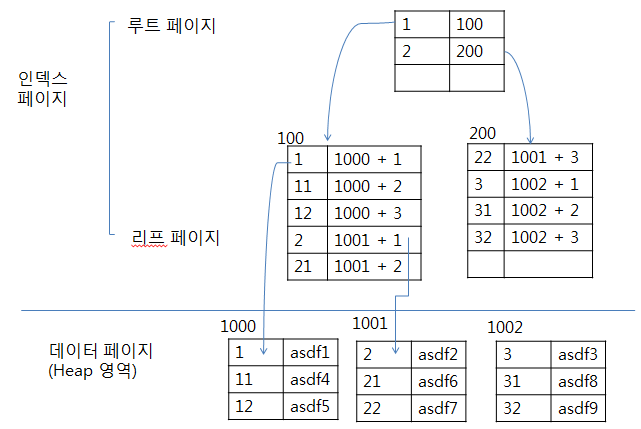
- Non-Clustered Index는 데이터 페이지를 건드리지 않고, 별도의 장소에 인덱스 페이지를 생성한다.
- Non-Clustered Index의 인덱스 페이지는 키값(정렬하여 인덱스 페이지 구성)과 RID로 구성된다.
- 검색하고자하는 데이터의 키 값을 루트 페이지에서 비교하여 리프 페이지 번호를 찾고, 리프 페이지에서 RID 정보로 실제 데이터의 위치로 이동한다. (RID 구조: 파일 식별자 + 페이지 번호 + 페이지 내의 로우 번호)
(EX : 12 검색위해 루트 페이지에서 파일 그룹번호 1에 해당하는 리프 페이지 100번으로 이동, 리프 페이지 100번에서 12는 데이터 페이지 1000번의 데이터페이지오프셋 3으로 되어 있음, 데이터 페이지 1000번으로 이동 후 3번째 컬럼으로 이동. 12, asdf5 검색 완료)
4. 클러스터 인덱스를 사용해야 할 때
- 특정한 컬럼을 기준으로 JOIN 이나 WHERE 문을 많이 이용할 때 해당 컬럼에 클러스터드 인덱스를 사용하면 좋습니다.
(단, 업데이트가 자주 일어나는 컬럼이 아니어야 합니다.)
- 특정한 컬럼에 대해 언제나 정렬된 데이터가 필요로 될 때, 해당 컬럼에 대해 매번 ORDER BY 구문을 이용하게 될 때 해당 컬럼에 클러스터드 인덱스를 사용하면 좋습니다.
5. 넌클러스터 인덱스를 사용해야 할 때
- 테이블의 로우를 필터링하기 위해 다수의 쿼리가 요구되고, WHERE 문이나 JOIN 문에서 다른 그룹의 컬럼들이 있을 때 논클러스터드 인덱스를 사용하면 좋습니다.
- 지속적으로 특정한 정렬 순서로 데이터를 출력한다면, 논클러스터드 인덱스로도 추가적 정렬 필요 없이 속도 향상 효과를 볼 수 있습니다.
- 특정한 기준(criteria)에 맞춘 열들만 인덱스를 걸고 싶다면, 논 클러스터드 인덱스 내부에 WHERE 조건을 추가할 수 있습니다.( Filter Non Clustered Index)
- 조회하려는 모든 컬럼이 인덱스에 포함되어 있을 때는 데이터 페이지까지 내려가지 않고도 모든 데이터 조회가 가능하기 때문에 Included column을 사용하는 것도 좋은 방안입니다. 다만, 동일한 데이터가 많은 컬럼에 인덱스를 걸면, 인덱스를 걸지 않는 것보다 느려질 수도 있다.
6. 인덱스 생성 이슈들(나쁜 영향을 주는 경우)
- 인덱스는 디스크 공간을 차지하고, SQL 프로세스 중 memory footprint에 영향을 줄 수 있습니다. (소요 저장 공간 : 클러스터 인덱스 < 넌클러스터 인덱스, 인덱스 테이블을 생성해야 하기 때문)
- insert시 데이터 재정렬 작업이 필요하므로 Insert가 많은 테이블엔 적합하지 않습니다.
- 클러스터드 인덱스의 컬럼들이 아닌 다른 컬럼 집합에 대해 ORDER BY 를 수행한다면, 클러스터드 인덱스는 아무런 도움이 되지 않습니다.
- 논클러스터 인덱스 생성 시, 컬럼을 많이 추가할수록 인덱스가 커지고 디스크에서 차지하는 크기도 늘어나므로 이러한 사항도 고려해야 합니다.
- 많은 인덱스는 성능을 해칠 수 있습니다.
( 2개의 논클러스터드 인덱스를 생성했다고 가정해보자. 첫번째 논클러스터드 인덱스가 컬럼 A와 B에 붙어있고, 두번째 논클러스터드 인덱스가 B와 C와 D에 붙어있다. 이 상태에서 만일 컬럼 A, C, D를 조회하면, SQL은 필요한 포인터를 찾기 위해 두개의 인덱스를 사용하고 테이블에서 그 데이터를 찾게 된다. 이러한 일은 쿼리 성능에 매우 안 좋은 영향을 준다.)
- 만일 bulk import를 할 필요가 있다면, 인덱스가 성능에 영향을 줄 수 있으므로 인덱스를 만들지 않는 것이 좋습니다.
📌 트랜잭션에 대해 설명해주세요
- 트랜잭션이란 데이터베이스의 상태를 변화시키는 하나의 논리적인 작업 단위입니다. 트랜잭션에는 여러개의 연산이 수행될 수 있습니다.
- 트랜잭션은 수행중에 한 작업이라도 실패하면 전부 실패하고, 모두 성공해야 성공이라고 할 수 있습니다.(데이터의 무결성으로 인해 데이터 작업 시 문제가 생기면, 데이터 작업을 하기 전 시점으로 데이터를 원상복구 시켜야 합니다.)
📌트랜잭션 격리 수준(Transaction Isolation Levels)에 대해서 설명해주세요
- 여러 트랜잭션이 동시에 처리될 때, 트랜잭션끼리 얼마나 서로 고립되어 있는지를 나타내는 것입니다.
즉, 동시에 여러 가지 트랜잭션이 진행될 때 서로 간의 정보에 접근할 수 있게 할 것인지 못하게 할 것인지를 결정하는 것입니다. 격리 수준에는 크게 4가지 레벨이 존재합니다.
1) READ UNCOMMITTED: 다른 트랜잭션에서 커밋되지 않은 내용도 참조할 수 있다.
(A 트랜잭션에서 데이터를 변경하는 중에 B에서 해당 데이터를 접근하고, A가 다시 롤백하면 B는 중간에 수정한 데이터로 읽음)
2) READ COMMITTED: 다른 트랜잭션에서 커밋된 내용만 참조할 수 있다.
(NON-REPEATABLE READ 부정합 문제가 발생 가능. 하나의 트랜잭션 내에서 똑같은 select 를 수행했을 경우 항상 같은 결과를 반환해야 한다는 repeatable read 정합성에 어긋날 수 있다.)
3) REPEATABLE READ: 트랜잭션에 진입하기 이전에 커밋된 내용만 참조할 수 있다.
4) SERIALIZABLE: 트랜잭션에 진입하면 락을 걸어 다른 트랜잭션이 접근하지 못하게 한다.(성능 매우 떨어짐)
📌 트랜잭션의 ACID에 대해서 설명해주세요
- 원자성(Automicity) : 트랜잭션에서 정의된 연산들은 모두 성공적으로 실행되던지 아니면 전혀 실행되지 않은 상태로 남아 있어야 한다. (All or Nothing)
- 일관성(Consistency) : 트랜잭션이 실행 되기 전의 데이터베이스 내용이 잘못 되어 있지 않다면 트랜잭션이 실행된 이후에도 데이터베이스의 내용에 잘못이 있으면 안된다. 일관적인 DB 상태를 유지한다.
- 고립성(Isolation) :트랜잭션이 실행되는 도중에 다른 트랜잭션의 영향을 받아 잘못된 결과를 만들어서는 안된다. 이런 성질을 만족하기 위해서는 트랜잭션을 순차적으로 실행해야 하지만 DBMS는 병렬 수행 하면서도 순차 수행의 결과를 보장.
- 지속성(Durability) :트랜잭션이 성공적으로 수행되면 그 트랜잭션이 갱신한 데이터베이스의 내용은 영구적으로 저장되며, 그 값을 참조할 수 있다. 트랜잭션이 성공적으로 수행되어 Commit 된다면 소프트웨어나 하드웨어에 장애가 생기더라도 그 결과는 보존 되어야 한다.
📌 정규화에 대해서 설명해주세요
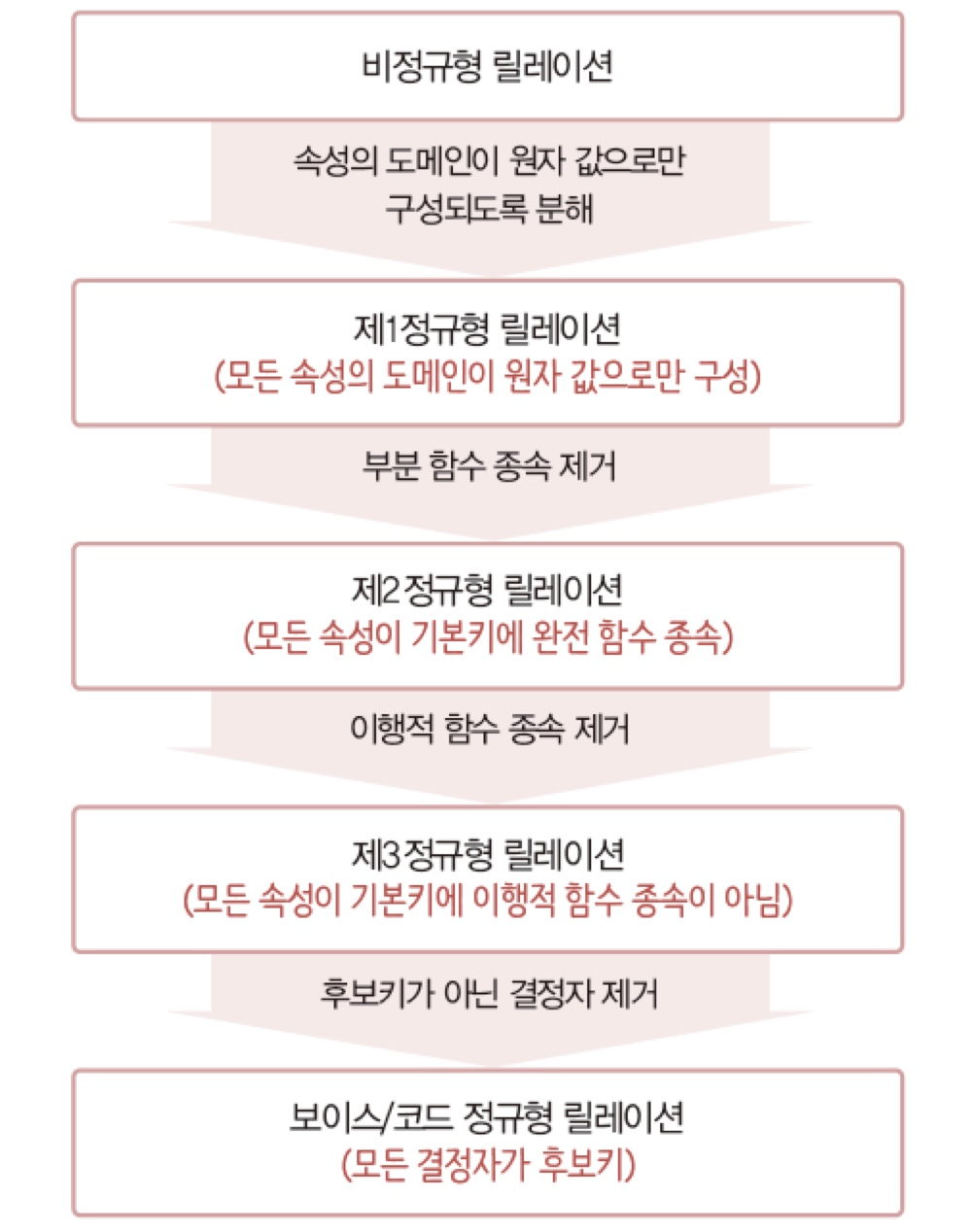
- 정규화는 하나의 릴레이션에 하나의 의미만 존재하도록 릴레이션을 분해하는 과정이며, 데이터의 일관성, 최소한의 데이터 중복, 최대한의 데이터 유연성을 위한 방법입니다.
- 제1 정규형 : 테이블의 컬럼이 원자 값(Atomic Value; 하나의 값)을 갖도록 분해합니다.
- 제2 정규형: 제1 정규형을 만족하고, 기본키가 아닌 속성이 기본키에 완전 함수 종속이도록 분해합니다.
※ 여기서 완전 함수 종속이란 기본키의 부분집합이 다른 값을 결정하지 않는 것을 의미
- 제3 정규형 : 제2 정규형을 만족하고, 이행적 함수 종속을 없애도록 분해합니다.
※ 여기서 이행적 종속이란 A → B, B → C가 성립할 때 A → C가 성립되는 것을 의미
- BCNF 정규형 : 제3 정규형을 만족하고, 함수 종속성 X → Y가 성립할 때 모든 결정자 X가 후보키가 되도록 분해합니다.
📌 정규화의 장단점과 이상현상에 대해 설명해주세요
장점
- 데이터베이스 변경 시 이상현상 문제점을 해결할 수 있습니다.
- 데이터베이스 구조 확장 시 정규화된 데이터베이스는 그 구조를 변경하지 않아도 되거나 일부만 변경해도 됩니다.
단점
- 분해로 인해 릴레이션 간 연산이 많아집니다. 그렇기 때문에 질의에 대한 응답 시간이 느려질 수 있습니다.
이상현상
- 이상 현상은 테이블을 설계할 때 잘못 설계하여 데이터를 삽입,삭제,수정할 때 생기는 논리적 오류를 말합니다.
1) 삽입 이상
- 자료를 삽입할 때 특정 속성에 해당하는 값이 없어 NULL을 입력해야 하는 현상
2) 갱신 이상
- 중복된 데이터 중 일부만 수정되어 데이터 모순이 일어나는 현상
3) 삭제 이상
- 어떤 정보를 삭제하면, 의도하지 않은 다른 정보까지 삭제되어버리는 현상
📌 역정규화를 하는 경우는 어떤 상황일까요?
- 정규화를 거치면 릴레이션 간 연산이 많아져 성능이 저하될 수 있다는 단점이 있습니다.
따라서 역정규화를 하는 경우는 성능 문제가 있는(읽기 작업이 많이 필요한) DB의 성능을 향상시켜야 할 경우 역정규화를 사용할 수 있습니다.
📌DB 락에 대해 설명해주세요.
DB Lock은 여러 사용자들이 같은 데이터를 동시에 접근하는 상황에서, 데이터의 무결성과 일관성을 지키고, 트랜잭션 처리의 순차성을 보장하기 위한 방법입니다.
공유락(LS, Shared Lock)
- Read Lock라고도 하는 공유락은 트랜잭션이 읽기를 할 때 사용하는 락입니다.
- 데이터를 읽기만하기 때문에 같은 공유락 끼리는 동시에 접근이 가능합니다.
- 공유락이 설정된 데이터에는 베타락을 사용할 수 없습니다.
- 주로 'S'로 표현합니다.
베타락(LX, Exclusive Lock)
- Write Lock라고도 하는 베타락은 데이터를 변경할 때 사용하는 락입니다.
- 트랜잭션이 완료될 때까지 유지되며, 베타락이 끝나기 전까지 어떠한 접근도 허용하지 않습니다.
- 베타락은 락이 해제될 때까지 다른 트랜잭션(읽기 포함)이 해당 리소스에 접근할 수 없습니다.
- 주로 'X'로 표기합니다.
업데이트 락(Update Lock)
- 데이터를 수정하기 위해 베타 락(X)을 걸기 전, 데드 락을 방지하기 위해 사용되는 락입니다.
- 일반적으로 업데이트 락은 UPDATE 쿼리의 필터(WHERE)가 실행되는 과정에서 적용됩니다.
- 서로 다른 트랜잭션에서 동일한 자원에 대해 읽기 쿼리 이후, 업데이트 쿼리를 적용하는 경우 컨버젼 데드락이 발생하는데, 이를 막기 위해 일부 SELECT 퀴리에서도 업데이트 락을 적용(WITH(UPDLOCK))하기도 합니다.
내재 락(Intent Lock)
- 내재 락은 앞서 소개한 락들과 사뭇 다른 기능을 합니다. 내재 락은 사용자가 요청한 범위에 대한 락(ex, 테이블 락)을 걸 수 있는지 여부를 빠르게 파악하기 위해 사용되는 락입니다. 내재 락은 공유 락과 베타 락 앞에 I 기호를 붙인 IS, IX, SIX 등이 있습니다.
- 사용자 A가 테이블의 하나의 로우(row)에 대해 베타 락(X)을 건 경우, 사용자 B가 테이블 전체에 대한 락을 걸기 위해서는(ex, 스키마 변경) 사용자 A의 트랜잭션이 끝날 때까지 기다려야 합니다.
그러나, 사용자 B가 테이블에 락(DDL Lock)을 걸 수 있는지 여부를 파악하기 위해 테이블에 존재하는 모든 로우와 관련된 락을 찾아보는 것은 매우 비효율적인 작업입니다.
따라서, 데이터베이스는 사용자 A가 로우에 베타 락(X)을 거는 시점에, 해당 로우의 상위 객체들(ex, 페이지, 테이블)에 대한 내재 락(IX)을 걸어, 다른 사용자가 더 큰 범위의 자원들에 대해 락을 걸 수 있는지 여부를 빠르게 파악할 수 있도록 돕습니다.
블로킹(Blocking)
- Lock간(베타-베타, 베타-공유)의 경합이 발생하여 특정 Transaction이 작업을 진행하지 못하고 멈춰선 상태를 의미합니다.
- 공유락끼리는 블로킹이 발생하지 않지만 베타락은 블로킹을 발생시킬 수 있는데, 블로킹을 해소하기 위해서는 이전의 트랜잭션이 완료(commit or rollback)되어야 합니다. 뒤에 들어온 트랜잭션은 이전 트랜잭션이 마무리되어야 이후 진행이 가능한데, 이런 경합은 성능에 좋지 않은 영향을 끼쳐서 경합을 최소화 해야 합니다.
교착상태(DeadLock)
- 교착상태는 두 트랜잭션이 각각 Lock을 설정하고 서로의 Lock에 접근하여 값을 얻어오려고 할 때 발생되는 무한대기상태를 의미합니다.
- 교착상태가 발생하면 DBMS가 두 트랜잭션중 하나에 에러를 발생시킴으로써 문제를 해결합니다. 교착상태가 발생할 가능성을 줄이기 위해서는 접근 순서를 동일하게 하는것이 중요합니다.
교착상태를 방지하기 위한 방법
- 트랜잭션을 자주 커밋한다.
- 정해진 순서로 테이블에 접근한다.
- SELECT ~ FOR UPDATE 의 사용을 피한다.
📌 옵티마이저(Optimizer)에 대해 설명해주세요.
- 옵티마이저는 가장 효율적인 방법으로 쿼리를 수행할 수 있도록 최적의 경로를 생성해주는 DBMS의 핵심엔진입니다.
- 쿼리를 실행하면 옵티마이저에서 여러 실행 계획을 세우고 최고이 효율을 가지는 실행계획을 판별한 후, 해당 실행계획에 따라 쿼리를 수행합니다.
📌 DB 튜닝(Tuning)이 무엇인지 그리고 튜닝의 3단계에 대해 설명해주세요.
- DB 튜닝이란 DB의 구조나, DB 자체, 운영체제 등을 조정하여 데이터베이스 시스템의 성능을 개선하는 작업을 말합니다.
- 튜닝은 DB 설계 튜닝 → DBMS 튜닝 → SQL 튜닝 단계로 진행할 수 있습니다.
- 1단계 - DB 설계 튜닝(모델링 관점)
- DB 설계 단계에서 성능을 고려하여 설계
- 데이터 모델링, 인덱스 설계
- 데이터파일, 테이블 스페이스 설계
- 데이터베이스 용량 산정
- 튜닝 사례 - 반정규화, 분산파일배치
- 2단계 - DBMS 튜닝(환경 관점)
- 성능을 고려하여 메모리나 블록 크기 지정
- CPU, 메모리 I/O에 관한 관점
- 튜닝 사례 - Buffer 크기, Cache 크기
- 3단계 - SQL 튜닝(App 관점)
- SQL 작성 시 성능 고려
- Join, Indexing, SQL Execution Plan
- 튜닝 사례 - Hash / Join
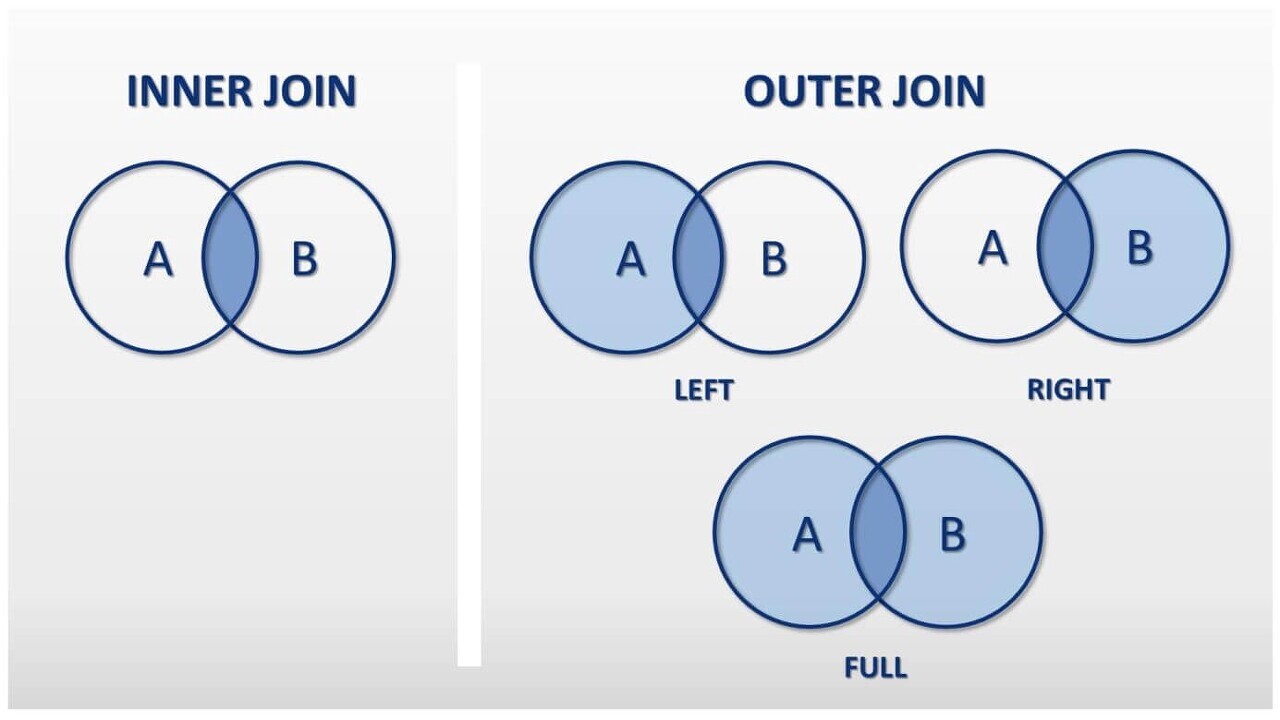
📌 inner join과 outer join의 차이를 설명해주세요.
- inner join 은 서로 연관된 내용만 검색하는 조인 방법으로, A와 B에 대해 수행하는 것은, A와 B의 교집합을 말합니다.
- outer join 은 한 쪽에는 데이터가 있고 한 쪽에는 데이터가 없는 경우, 데이터가 있는 쪽의 내용을 전부 출력하는 방법입니다.
outer join에는 LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN이 있습니다.
📌 group by의 역할에 대해 설명해주세요.
- 특정 컬럼을 기준으로 연산한 결과를 집계 키로 정의하여 그룹을 짓는 역할을 합니다. 집합 연산자는 COUNT, SUM, AVG, MAX, MIN 등이 있고, DISTINCT와 같이 중복 데이터를 제거하는 특징이 있습니다.
📌 DELETE, TRUNCATE, DROP의 차이를 설명해주세요.
DELETE는 데이터는 지우지만 테이블 용량은 줄어들지 않고 원하는 데이터만 골라서 지울 수 있습니다. 삭제 후 되돌릴 수 있습니다.
TRUNCATE는 전체 데이터를 한번에 삭제하는 방식입니다. 테이블 용량이 줄어들고 인덱스 등도 삭제되지만 테이블은 삭제할 수 없고, 삭제 후 되돌릴 수 없습니다.
DROP은 테이블 자체를 완전히 삭제하는 방식(공간, 인덱스, 객체 모두 삭제)입니다. 삭제 후 되돌릴 수 없습니다.
📌 ORM에 대해 설명해주세요.
- Object Relational Mapping ,객체-관계 매핑의 줄임말로, 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결)해주는 것을 의미합니다.
- 객체 지향 프로그래밍은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용하는데, 객체 모델과 관계형 모델 간에 불일치가 존재하는 경우, ORM을 통해 객체 간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결할 수 있습니다.
장점
- 객체 지향적인 코드로 인해 더 직관적이고 비즈니스 로직에 더 집중할 수 있게 도와준다.
- DBMS에 대한 종속성이 줄어든다.
- 재사용 및 유지보수의 편리성이 증가
단점
- 완벽한 ORM 으로만 서비스를 구현하기가 어렵다.
- 프로시저가 많은 시스템에선 ORM의 객체 지향적인 장점을 활용하기 어렵다.
- 이미 프로시저가 많은 시스템에선 다시 객체로 바꿔야하며, 그 과정에서 생산성 저하나 리스크가 많이 발생할 수 있다.
📌having과 where의 차이를 설명해주세요.
having은 그룹화 또는 집계가 발생한 후 필터링하는데 사용되고, where은 그룹화 또는 집계가 발생하기 전에 필터링하는데 사용됩니다.
집계 함수(COUNT, SUM, AVG, MAX, MIN 등)는 having절과 함께 사용할 수 있으나,
where절은 사용할 수 없습니다.( 집계함수를 사용할 수 있는 GROUP BY 절보다 WHERE절이 먼저 수행)
💡 Elastic Search의 키워드 검색과 RDBMS의 LIKE 검색의 차이에 대해 설명해주세요.
- RDBMS는 단순 텍스트매칭에 대한 검색만을 제공해 동의어나 유의어 같은 검색은 불가능합니다.
- (MySQL 최신 버전에서 n-gram 기반의 Full-Text 검색을 지원하긴 하지만, 한글 검색의 경우 아직 많이 빈약한 감이 있습니다.)
- 하지만 엘라스틱 서치는 동의어나 유의어를 활용한 검색이 가능하며, 비정형 데이터의 색인과 검색이 가능하고, 역색인 지원으로 매우 빠른 검색이 가능합니다.
※ Full-Text : 이미지, CSS, 글 등의 복합적으로 이뤄진 컨텐츠에서 순수하게 텍스트만 추출한 데이터를 의미. 이 과정을 보통 크롤링으로 구현함 ( 엘라스틱 서치의 검색엔진엔 크롤러가 빠져있어 별도로 구축해야함)
📌Elastic Search의 인덱스구조와 RDBMS의 인덱스 구조의 차이에 대해 설명해주세요
📌Redis에 대해서 간단히 설명해주세요
📌CAP 이론과, Eventual Consistency에 대해서 설명해주세요.
성능 최적화 (RBO, CBO)
만약 어떤 친구가 성별 컬럼을 인덱스로 걸려고 한다면?
📌Hint에 대해 설명해주세요
- 힌트란 SQL을 튜닝하기 위한 지시구문입니다. 옵티마이저가 최적의 계획으로 SQL문을 처리하지 못하는 경우에 개발자가 직접 최적의 실행 계획을 제공하는 것입니다.
1)JOIN힌트 : 사용될 조인 기법을 지정
- INNER와 JOIN 사이에 JOIN hint이름을 나열한다. { LOOP | MERGE | HASH }
SELECT *
FROM title a
INNER HASH JOIN publishers b
ON a.pub_id=b.pub_id
또는
SELECT *
FROM title a
INNER JOIN publishers
ON a.pub_id = b.pub_id
OPTION (HASH JOIN);두 방식의 차이점은 아래의 방법처럼 OPTION 절을 사용하여 hint 를 주는것이 우선순위가 높다
2) 인덱스힌트 : 검색이나 정렬을 수행하기 위해 사용되어야 하는 특정 인덱스들을 지정
- 문법
SELECT select_list
FROM table [ (INDEX ({index_name | index_id} [, index_name | index_id ... ]))]1. 0번 인덱스를 타지 않게 하는 방법
SELECT au_lname, au_fname
FROM authors WITH (INDEX(0))
WHERE au_lname LIKE 'C%' - INDEX 0번은 인덱스를 타지 않게 하는 옵션. INDEX 1번은 클러스터된 인덱스를 사용하게 하는 옵션이며
2번부터는 생성된 인덱스마다 번호가 부여됩니다.
2. 인덱스 번호로 인덱스를 사용하게 하는 방법 (2,3번 인덱스를 사용, 테이블에 인덱스 번호가 있는지 확인 필요)
SELECT au_lname, au_fname
FROM authors WITH (INDEX(2,3))
WHERE au_lname LIKE 'C%'
3. 선택한 인덱스를 사용하게 하는 방법 1
SELECT au_lname, au_fname
FROM authors WITH (INDEX(aunmind))
WHERE au_lname LIKE 'C%'
4. 선택한 인덱스를 사용하게 하는 방법 2
SELECT au_lname, au_fname
FROM authors WITH (INDEX(idx_nci_fname, idx_nci_lname))
WHERE au_lname LIKE 'C%'
3) 쿼리 처리 힌트 : 사용되어야 할 특정 처리 전략을 지정
-- GRUOP BY할때 HASH GROUP hashing 기법으로 그룹핑한다.
SELECT type,count(*)
FROM titles
GROUP BY type
OPTION (HASH GROUP)4) 잠금힌트 : 사용되어야 할 특정 잠금모드를 지정
FROM 테이블 WITH(HOLDLOCK)
FROM 테이블 WITH(UPDLOCK)
📌 클러스터링과 리플리케이션의 차이점에 대해 설명해주세요
1) 리플리케이션
- 여러 개의 DB를 권한에 따라 수직적인 구조(Master-Slave)로 구축하는 방식이다.
- 비동기 방식으로 노드들 간의 데이터를 동기화한다.
- 장점: 비동기 방식으로 데이터가 동기화되어 지연 시간이 거의 없다.
- 단점: 노드들 간의 데이터가 동기화되지 않아 일관성있는 데이터를 얻지 못할 수 있다.
2) 클러스터링
- 여러 개의 DB를 수평적인 구조로 구축하여 Fail Over한 시스템을 구축하는 방식이다.
- 동기 방식으로 노드들 간의 데이터를 동기화한다.
- 장점: 1개의 노드가 죽어도 다른 노드가 살아 있어 시스템을 장애없이 운영할 수 있다.
- 단점: 여러 노드들 간의 데이터를 동기화하는 시간이 필요하므로 Replciation에 비해 쓰기 성능이 떨어진다.
📌인덱스 헌팅에 대해 설명해주시겠어요?
인덱스 헌팅은 인덱스 수집을 향상시켜 데이터베이스 성능뿐만 아니라 쿼리 성능을 향상시키는 프로세스입니다.
인덱스 헌팅은 다음을 통해 쿼리 성능을 향상시킵니다.
- 쿼리 최적화 프로그램을 사용하여 워크로드와 쿼리를 조정합니다.
- 인덱스 및 쿼리 배포의 성능 및 효과 관찰
📌 검사점(checkpoint)에 대해 설명해주시겠어요?
- CheckPoint 란 SQL Server 데이터베이스 엔진이 예기치 않은 종료 또는 충돌 후 복구과정에서 로그에 포함된 변경 내용의 적용을 시작할 수 있는 올바른 지점을 만드는 것을 의미합니다.
성능상의 이유로 SQL Server 는 변경이 있을 때마다 메모리에서 페이지를 수정하며 이러한 페이지를 실시간으로 디스크에 기록하지 않습니다. 대신 SQL Server CheckPoint 는 메모리 상의 Dirty 된 페이지와 메모리의 트랜잭션 로그 정보들을 디스크로 동기화 하는 작업을 정기적으로 수행합니다.
이러한 작업은 위에서 말했던 것처럼 복구 시간을 단축하기 입니다.
CheckPoint 설정 종류
| 속성 | 구문 | 설명 |
| 자동 | EXEC sp_configure 'recovery interval', 초 ; | 최대 제한 시간에 맞게 백그라운드에서 자동으로 실행 |
| 간접 | ALTER DATABASE database_name SET TARGET_RECOVERY_TIME = 숫자 SECONDS | MINUTES ; | 지정된 데이터베이스의 사용자 지정 대상 복구 시간에 맞게 백그라운드에서 실행 |
| 수동 | CHECKPOINT 초 | 검사점을 완료하기 위해 요청된 시간을 지정 |
📌 카탈로그 / 데이터 웨어하우스 / 데이터 사전/ 병행제어란 무엇인가요?
1) 시스템 카탈로그
- DB에 포함되는 모든 데이터 객체들에 대한 정의나 명세 관련 정보를 유지관리하는 시스템 DB입니다.
- 데이터 사전, 자료사전, 메타 DB, 시스템 DB와 동의어입니다.
- 검색은 가능하나 수정은 불가능하며, DBMS 스스로가 생성하고 유지하는 DB입니다.
2) 데이터 디렉토리(Data Directory)
- 시스템 DB(시스템 카탈로그)에 수록된 데이터를 실제로 접근하는데 필요한 정보를 관리합니다.
- 시스템만이 접근 가능합니다.
3) 데이터 웨어하우스
- 기업의 의사결정에 도움을 주기 위해, 현재 뿐만 아니라 시간에 맞춰 과거와 현재의 DB를 모두 유지하며 결정에 도움을 주는 DB입니다.
- 사용자의 의사 결정에 도움을 주기 위하여, 기간시스템의 데이터베이스에 축적된 데이터를 공통의 형식으로 변환해서 관리하는 데이터베이스를 말합니다.
- ETL(Extract, Transform, Load) 이란 데이터 웨어하우스 구축 시 데이터를 운영 시스템에서 추출하여 가공(변환, 정제)한 후 데이터 웨어하우스(DW)에 적재하는 과정을 말합니다. 일반적으로 발생하는 데이터 변환에는 필터링, 정렬, 집계, 데이터 조인, 데이터 정리, 중복 제거 및 데이터 유효성 검사 등의 다양한 작업이 포함된다.
- Extract: 하나 또는 그 이상의 데이터 원천들로 부터 데이터 추출
- Transform: 추출한 데이터를 요구사항에 맞게 변경하는 작업
- Load: 변형 단계의 처리가 완료된 데이터를 특정 목표 시스템에 적재
4) 데이터 레이크(Data Lake)
- 정형, 반정형 및 비정형 데이터를 비롯한 모든 가공되지 않은 다양한 종류의 데이터를 한 곳에 모아둔 중앙 리포지토리
- 빅데이터를 효율적으로 분석하고 사용하고자 다양한 영역의 Raw 데이터를 한 곳에 모아서 관리하고자 하는 목적입니다.
5)데이터 마트(Data Mart)
- 금융, 마케팅 또는 영업과 같은 특정 팀 또는 사업 단위의 요구를 충족시키는 데이터 웨어하우스입니다.
- 규모가 더 작고, 집중적이며 사용자 커뮤니티에 가장 잘 맞는 데이터 요약을 포함할 수 있습니다. 데이터 마트는 데이터 웨어하우스의 일부일 수 있습니다.
📌 결정 규칙에 대해 설명해주세요
1. 규칙기반 옵티마이저(Rule-Based Optimizer, RBO)
- 연산자, 인덱스의 유무, 조건절형태 등 정해진 규칙의 우선순위에 따라 실행계획을 생성한다.
- 테이블의 레코드 건수나 선택도 등을 고려하지 않고 옵티마이저에 내장된 우선순위에 따라 실행 계획을 수립하는 방식이므로, 통계정보(레코드 건수, 컬럼 분포도)를 조사하지 않고, 실행계획이 수립되기 때문에 쿼리가 거의 항상 같은 실행 방법을 만들어낸다.
규칙기반 최적화는 인덱스의 통계정보가 거의 없고 상대적으로 느린 CPU 연산탓에 비용 계산 과정이 부담스러웠기 때문에 사용되던 최적화 방법이다. 현재는 거의 대부분의 RDBMS가 비용 기반의 옵티마이저를 채택하고 있다.
- 인덱스를 이용한 액세스 방식 > 전체 테이블 액세스 방식
- 조인 칼럼에 대한 인덱스가 양쪽 테이블에 모두 존재할 때, 우선순위가 높은 테이블 선택
- 만약 조인 테이블의 우선순위가 동일하지않다면, FROM 절에 나열된 테이블의 역순으로 수행
- 조인 칼럼에 대한 인덱스가 양쪽 테이블에 모두 존재할 때, 우선순위가 높은 테이블을 선택
2. 비용기반 옵티마이저(Cost-Based Optimizer, CBO)
- 쿼리를 수행하는데 소요되는 예상 비용을 바탕으로 실행계획을 생성한다. 통계정보, DBMS 설정정보, DBMS 버전 등의 차이로 인해 똑같은 SQL문이라도 서로 다른 실행계획이 생성될 수 있다.
SELECT *
FROM employees e, dept_emp de
WHERE e.emp_no=de.emp_no;1 ) 두 칼럼 모두 각각 인덱스가 있는 경우
각 테이블의 레코드 건수에 따라 employees 가 드라이빙 테이블이 될 수도 있고, dept_emp 테이블이 드라이빙 테이블이 될 수도 있다.
2) dept_emp.emp_no 에만 인덱스가 있는 경우
employees 테이블의 반복된 풀 스캔을 막기 위해 employees 테이블을 드라이빙 테이블로 선택하고, 인덱스가 있는 dept_emp 테이블을 드리븐 테이블로 조인을 수행하도록 실행 계획을 수립한다.
3) employees.emp_no에만 인덱스가 있는 경우
ept_emp 테이블을 드라이빙 테이블로, employees 테이블을 드리븐 테이블로 선택하게 된다.
4) 두 칼럼 모두 인덱스가 없는 경우
어느 테이블을 드라이빙으로 선택하더라도 드리븐 테이블의 풀 스캔은 발생하기 때문에 스캔되는 레코드 수에 따라 적절히 드라이빙 테이블을 선택하게 된다.
조인이 수행될때 양쪽 테이블의 칼럼에 모두 인덱스가 없을 때만 드리븐 테이블을 풀스캔한다. 나머지 경우에는 드라이빙 테이블을 풀 테이블 스캔을 사용할 수는 있어도 드리븐 테이블을 풀 테이블 스캔으로 접근하는 실행 계획은 옵티마이저가 거의 만들어내지 않는다.
비용 기반 최적화는 쿼리를 처리하기 위한 여러 가지 가능한 방법을 만들고, 각 단위 작업의 비용(부하) 정보와 대상 테이블의 예측된 통계 정보를 이용해 각 실행 계획별 비용을 산출한다. 이렇게 산출된 각 실행 방법별로 최소 비용이 소요되는 처리 방식을 선택해 최종 쿼리를 실행한다.
응용 용어
1. 선택도(selectivity)
- 테이블의 특정 열을 기준으로 해당 열의 조건절 (WHERE 절 조건문)에 따라 선택되는 데이터 비율
- 해당 열에 중복되는 데이터가 많다면 '선택도가 높다' / 해당 열에 중복되는 데이터가 적으면 '선택도가 낮다'
- 낮은 선택도가 대용량 데이터에서 원하는 데이터만 골라 낼 수 있기 때문에 낮은 선택도를 가지는 열은 데이터를 조회하는 SQL 문에서 원하는 데이터를 빨리 찾기 위한 인덱스 열을 생성할 때 주요 고려대상
- => 선택도가 낮은 대상을 인덱스로 뽑는게 좋다
선택도 = 선택한 데이터 건수 ÷ 전체 데이터 건수
일반화된 선택도 = 1 ÷ DISTINCT(COUNT 열 명)2. 카디널리티(cardinality)
- '하나의 데이터 유형으로 정의되는 데이터 행의 개수'
- 전체 데이터에 접근한 뒤 출력될 것이라 예상되는 데이터 건수를 의미. 전체 행에 대한 특정 열의 중복 수치를 나타내는 지표로 자주 활용됨
- 중복도가 높으면 -> 카디널리티가 낮고, 중복도가 낮으면 -> 카티널리티가 높다
- 카디널리티가 높은 대상을 인덱스로 뽑는게 좋다
- - 카디널리티 = 전체 데이터 건수 x 선택도
ex) 전체 데이터가 100건인 테이블에서 기본키가 학번인 열을 대상으로 카디널리티를 구한다고 가정하자. 학번 열의 카디널리티는 100 × 0.01 = 1건 (모든 학번의 데이터값이 고유한 만큼 1건의 데이터만 출력되리라 예측 가능)
ex2) 일상생활에서의 카디널리티 적용 사례
• 주민등록번호: 카디널리티 높음
• 이름 카디널리티 중간
• 성별: 카디널리티 낮음
https://gmlwjd9405.github.io/2019/02/01/orm.html
https://earth-ing.tistory.com/55
https://1-day-1-coding.tistory.com/2
https://hyonee.tistory.com/41
https://dev-coco.tistory.com/158#%F-%-F%--%A-%C-%A-%EB%-D%B-%EC%-D%B-%ED%--%B-%EB%B-%A-%EC%-D%B-%EC%-A%A-%EC%-D%--%--%ED%-A%B-%EC%A-%--%EC%--%--%--%EB%-C%--%ED%--%B-%--%EC%--%A-%EB%AA%--%ED%--%B-%EC%A-%BC%EC%--%B-%EC%-A%---
출처: https://mangkyu.tistory.com/93 [MangKyu's Diary]
https://velog.io/@gillog/SQL-Clustered-Index-Non-Clustered-Index
https://bomwo.cc/posts/Datawarehouse/
'전공 > DB' 카테고리의 다른 글
| [데이터베이스] 전공 필기 시험 정리 (0) | 2022.04.01 |
|---|---|
| MySQL튜닝6) 튜닝 심화 예제 (0) | 2022.02.16 |
| MySQL튜닝5) 튜닝 기본 예제 (0) | 2022.02.08 |
| MySQL튜닝4) 실행계획 살펴보기2 (0) | 2022.01.26 |
| MySQL튜닝3) 실행계획 살펴보기1 (0) | 2022.01.19 |



