1. 실습 데이터 세팅
- 실습 데이터 URL : https://github.com/7ieon/SQLtune
- 실습 데이터 정보



2. JOIN / 서브쿼리 변형하여 SQL문 재작성으로 착한 쿼리 만들기
1) 처음부터 모든 데이터를 가져오지 않기
# 쿼리문
- 사원번호가 10001 ~ 10100번까지인 사원들의 평균연봉, 최고연봉, 최저연봉을 구하는 쿼리
# AS_IS
-- 3.593 sec / 0.000 sec
select 사원.사원번호,
급여.평균연봉,
급여.최고연봉,
급여.최저연봉
from 사원,
( select 사원번호,
round(avg(연봉),0) as 평균연봉,
round(max(연봉),0) as 최고연봉,
round(min(연봉),0) as 최저연봉
from 급여
group by 사원번호
) 급여
where 사원.사원번호 = 급여.사원번호
and 사원.사원번호 BETWEEN 10001 AND 10100
- id = 1인 사원 테이블과 <derived 2>테이블이 조인되었음
- <derived 2> 테이블은 id = 2이고 select_type 항목이 DERIVED로 된 급여 테이블로 그루핑 결과를 생성한 임시 테이블
- 이후 where 절의 사원.사원번호 = 급여.사원번호 구문으로 데이터 추출 및 조인 수행
# Tuning
- type의 index : 인덱스 풀 스캔을 수행
=> 급여 테이블을 조건절 없이 grouping 수행하므로 지나치게 많은 데이터를 접근함 (row항목에 2629077을 통해 급여 테이블의 모든 항목을 탐색함을 알 수 있음)
=> 사원번호가 10001 ~ 10100인 사원의 급여 정보만 필요함
# TO_BE
-- 0.016 sec / 0.000 sec
select 사원.사원번호,
(select round(avg(연봉),0)
from 급여 as 급여1
where 사원번호 = 사원.사원번호) as 평균연봉,
(select round(max(연봉),0)
from 급여 as 급여2
where 사원번호 = 사원.사원번호) as 최고연봉,
(select round(min(연봉),0)
from 급여 as 급여3
where 사원번호 = 사원.사원번호) as 최저연봉
from 사원
where 사원.사원번호 between 10001 and 10100
- id = 1인 사원테이블에 가장 먼저 접근하고, 사원테이블의 사원번호 조건을 SELECT절에서 3개의 스칼라 서브쿼리로 받으므로 급여1,2,3테이블은 DEPENDENT SUBQUERY가 된다.
- DEPENDENT 유형은 지나치게 자주 반복 호출될 경우 지양해야 하지만, 다음처럼 100건의 데이터만 추출되는 경우에는 급여 테이블에 100번만 접근하므로 성능 측면에서 비효율적인 부분은 없다.
2) 비효율적인 페이징을 수행하지 않도록 주의하기
# 쿼리문
- 사원번호가 10001번~50000인 사원 데이터를 사원번호 기준으로 GROUPING 한 뒤, 연봉 합계 기준으로 내림차순하는 쿼리. 이때 LIMIT 연산자를 사용하여 150번째 데이터부터 10건의 데이터만 가져오도록 제한
# AS_IS
-- 0.546 sec / 0.000 sec
select 사원.사원번호, 사원.이름, 사원.성, 사원.입사일자
from 사원,
급여
where 사원.사원번호 = 급여.사원번호
and 사원.사원번호 between 10001 and 50000
group by 사원.사원번호
order by sum(급여.연봉) desc
limit 150,10;
- 사원 테이블은 grouping 및 정렬 연산을 위해 임시 테이블(extra: Using temporary)를 생성한 뒤, 정렬(extra : using filesort)를 수행
=> 전체 데이터에 대해 grouping 및 정렬을 수행한 후 마지막으로 10건의 데이터만 조회하는 건 비효율적일 수 있다.
# TO_BE
-- 0.375 sec / 0.000 sec
select 사원.사원번호, 사원.이름, 사원.성, 사원.입사일자
from ( select 사원번호
from 급여
where 사원번호 between 10001 and 50000
group by 사원번호
order by sum(급여.연봉) desc
LIMIT 150,10) 급여,
사원
where 사원.사원번호 = 급여.사원번호;

- 급여 테이블의 grouping / order by / limit 작업을 from절의 인라인 뷰로 작성하고, 그 후 사원 테이블과 조인하여 데이터 건수를 줄임
- 실행계획의 <derived2> 테이블은 id = 2인 급여 테이블이며, where절의 사원번호 BETWEEN 10001 AND 50000 조건절에 따라 index range scan을 수행
3) 필요 이상으로 많은 정보를 가져오지 않도록 하기
# 쿼리문
- 성별이 남이고, 사원번호가 300,000을 초과하는 사원 데이터를 사원테이블로부터 가져온 뒤, 부서관리자 테이블과 외부 조인 수행한 결과 개수를 출력하는 쿼리
#AS_IS
-- 0.328 sec / 0.000 sec
select count(사원번호) as 카운트
from ( select 사원.사원번호, 부서관리자.부서번호
from (select *
from 사원
where 성별 = 'M'
and 사원번호 > 300000
) 사원
left join 부서관리자 on 사원.사원번호 = 부서관리자.사원번호
) 서브쿼리;
- 드라이빙 테이블인 사원 테이블은 "사원번호 > 300000" 조건 때문에 index range scan을 수행하며, primary key를 통해 데이터에 접근
- 부서관리자 테이블은 left join에 따라 primary key를 활용하여 1건의 데이터씩 접근
# Tuning
- 최종 결과로 원하는 것이 사원 테이블의 사원데이터 건수인데, 부서관리자 테이블과 외부 조인하는 조건은 불필요함
# TO_BE
-- 0.094 sec / 0.000 sec
select count(사원번호) as 카운트
from 사원
where 성별 = 'M'
and 사원번호 > 300000
- 튜닝 전 쿼리에 있었던 부서관리자 테이블의 연산 작업이 제거
- 또한 외부조인을 이용한 데이터 접근이 불필요하므로, 이전엔 사원 테이블의 rows 항목이 약 15만건이었지만 이번에는 5만건의 데이터만 접근
4) 대량의 데이터를 가져와 조인하는 경우, 해당 조인이 반드시 필요한 조건인지 확인하기
# 쿼리문
- 부서의 관리자가 소속된 부서번호를 조회하면서 부서사원_매핑 테이블에도 있는 부서번호를 출력하는 쿼리
#AS_IS
- 0.656 sec / 0.000 sec
select distinct 매핑.부서번호
from 부서관리자 관리자,
부서사원_매핑 매핑
where 관리자.부서번호 = 매핑.부서번호
order by 매핑.부서번호
- DISTINCT 연산으로 최종 부서번호 결과에서 중복 제거하고 ORDER BY 절로 오름차순 정렬함
- 먼저 접근하는 관리자 테이블은 index full scan(type : index)으로 데이터 접근
# Tuning
- 쿼리 결과로 중복 제거된 부서번호 column만 조회하려 함
- 굳이 두 테이블을 부서번호 column으로 조인하지 않고 둘중 하나의 테이블은 부서번호가 존재하는지 여부만 확인해도 됨
# TO_BE
-- 0.000 sec / 0.000 sec
select 매핑.부서번호
from (select distinct 부서번호
from 부서사원_매핑
) 매핑
where exists ( select 1
from 부서관리자 관리자
where 부서번호 = 매핑.부서번호)
order by 매핑.부서번호
- 관리자 테이블과 <derived 2> 테이블이 조인되며, <derived 2>테이블은 id = 2인 행의 인라인 뷰인 부서사원매핑 테이블에서 distinct 작업을 수행한 테이블이다.
- 부서사원_매핑 테이블은 distinct 작업을 위해 I_부서번호 index로 정렬한 뒤 중복을 제거( extra: Using index for group-by)
- 부서관리자 테이블은 전체 데이터를 index full scan한 뒤, 드리븐 테이블인 매핑 테이블과 조인한다. 이 때 exists 연산자로 비교할 부서번호가 있다면 이후로 동일한 부서번호 데이터는 확인하지 않고 건너뛰므로 extra 항목에 LooseScan으로 표기
(참고, LooseScan : IN (subquery) 에서 subquery에 중복된 값이 나타날때 중복값을 제거하는 최적화를 진행했을때 표현)
3. 인덱스 조정으로 착한 쿼리 만들기
1) 인덱스 없이 작은 규모의 데이터를 조회하지 않도록 하기
# 쿼리문
- 이름이 Georgi이고 성이 Wielonsky인 사원 정보를 출력하는 쿼리
# AS_IS
-- 0.563 sec / 0.000 sec
select *
from 사원
where 이름 = 'Georgi' and 성 = 'Wielonsky'
- 실행계획에 따르면, 사원 테이블을 table full scan하여 데이터를 가져온다. 스토리지 엔진에서 가져온 전체 데이터 중 where 조건에 해당한 데이터를 추출함(extra : using where)
# Tuning
- 단 1건의 데이터를 가져오고자 테이블을 모두 스캔하는 방식은 비효율적일 수 있음
- 조건절에 해당하는 열들이 자주 호출된다면, 인덱스로 빠른 데이터 접근을 유도할 수 있다.
- 이름 column과 성 column 중 데이터 범위를 더 축소할 수 있는 성 column을 선두 열로 index를 생성할 수 있다.
# TO_BE
-- 0.000 sec / 0.000 sec
alter table 사원 add index I_사원_성_이름(성,이름);
select *
from 사원
where 이름 = 'Georgi' and 성 = 'Wielonsky'
- (성,이름) column으로 index 생성 후, 같은 쿼리 실행 시 index로 인덱스 스캔을 수행하여 데이터에 접근하므로 1거느이 데이터만 최종 반환
2) 조건 절에 쓰이는 컬럼이 인덱스를 사용하도록 인덱스를 생성해보기
#쿼리문
- 이름이 'Matt'이거나 입사일자가 '1987년3월31일'인 사원 정보를 조회하는 쿼리
# AS_IS
-- 0.281 sec / 0.000 sec
select *
from 사원
where 이름 = 'Matt' or 입사일자 = '1987-03-31'
- 사원 테이블은 table full scan으로 처리되며, 스토리지엔진으로 모든 데이터를 가져온 뒤, MySQL엔진에서 2개 조건절을 활용하여 데이터를 필터링
# Tuning

- 조건절에 해당하는 데이터 분호를 확인해 볼때, 이름 = 'Matt'에 해당하는 데이터는 233건이고 입사일자 = '1987-03-31'에 해당하는 데이터는 111건
- 전체 데이터는 30만건이므로, 이름과 입사일자 column의 조건절에서 조회하는 데이터 건수는 상대적으로 적다.
=> 소량의 데이터를 가져올 땐 index full scan이 더 효율적이다.
=> I_이름 index를 생성하여 각 조건절이 각각의 index를 사용해 접근할 수 있도록 함
# TO_BE
-- 0.078 sec / 0.000 sec
alter table 사원 add index I_이름(이름);
select *
from 사원
where 이름 = 'Matt' or 입사일자 = '1987-03-31';
- 2개의 조건절이 각각 index scan으로 수행되고 각 결과가 병합되는 index_merge가 수행됨
(참고, 만약 where 절 ~ OR 구문에서 조건절이 동등 조건이 아닌 범위조건(LIKE, BETWEEN)이면 INDEX_MERGE로 처리되지 않을 수 있으므로 실행계획을 확인한 뒤, UNION이나 UNION ALL으로 구분하는걸 고려해야 함)
3) 인덱스가 있는 컬럼에서 큰 규모의 데이터 변경 발생 시, 인덱스 삭제 고려하기
# 쿼리문
- 사원출입기록 테이블의 B출입문 출입 이력들을 X출입문으로 변경하는 쿼리
# AS_IS
-- 21.938 sec
update 사원출입기록
set 출입문 = 'X'
where 출입문 = 'B'
- primary key로 테이블에 접근한 뒤, 출입문 = 'B' 조건에 해당하는 데이터만 'X'로 변경(select type : update)
# Tuning
- update문은 수정할 데이터에 접근한 뒤 set절의 수정값으로 변경하기 때문에 데이터를 접근하는데 있어 인덱스의 존재 여부는 고려 대상
- 조회한 데이터를 변경하는 범위에는 인덱스 또한 포함되므로, 인덱스가 많은 테이블의 데이터를 변경 시 성능적으로 불리
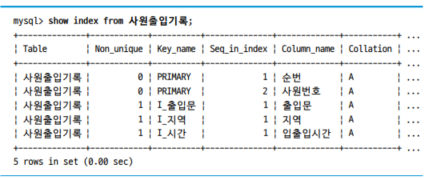
- 사원출입기록 테이블과 I_출입문 index에 매번 update문을 수행하므로 수십 초가 소요됨
- 사원출입기록 테이블과 같은 이력용 테이블에선 보통 지속적인 데이터 저장만 이루어지므로, 애플리케이션을 통한 I_출입문 index의 활용도가 없다면 삭제 고려
- 혹은, update 작업이 새벽(서비스에 미치는 영향이 적은 시간대에 수행)에 수행되는 배치성 작업이라면, 인덱스를 일시적으로 삭제한 뒤 대량 업데이트 후 다시 생성하는 방식으로도 효율성을 높일 수 있음
# TO_BE
-- 5.156 sec
alter table 사원출입기록 drop index I_출입문;
update 사원출입기록
set 출입문 = 'X'
where 출입문 = 'B';
- 인덱스 삭제 후 primary key로 데이터에 접근하여 데이터를 변경함
4) 비효율적인 인덱스는 수정하기 (인덱스의 컬럼 순서 바꾸기)
# 쿼리문
- 사원 테이블에서 성별이 남성이고, 성이 'Baba'인 정보를 조회하는 쿼리
# AS_IS
-- 0.047 sec / 0.000 sec
select 사원번호, 이름, 성
from 사원
where 성별 = 'M' and 성 = 'Baba';
# Tuning
- 조회되는 건수가 적고 실행 시간이 짧다 보니 자칫 튜닝할 필요가 없다고 느낄 수 있으나, 적절한 방식으로 데이터에 접근하는지 확인 필요

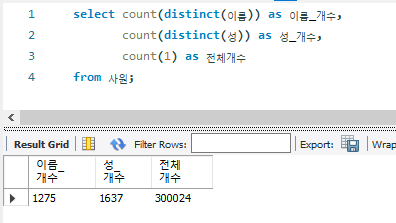
- column의 개수를 보면, 성 column은 1637건인데 비해 성별은 2건에 불과
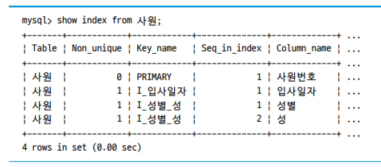
- I_성별_성 index를 확인해보면, 데이터가 다양하지 않은 성별 column을 선두로 구성한 index보단 더 다양한 종류값을 가지는 성 column을 먼저 활용하면 데이터 접근 범위를 줄일 수 있다.
# TO_BE
-- 0.031 sec / 0.000 sec
alter table 사원 drop index I_성별_성, add index I_성_성별(성,성별);
select 사원번호, 이름, 성
from 사원
where 성별 = 'M' and 성 = 'Baba'
- 기존 I_성별_성 index에서 구성된 '성별 + 성 ' 순서를 ' 성 + 성별' 의 순서로 변경한다.
4. 적절한 테이블 및 열 속성 설정으로 착한 쿼리 만들기
1) 잘못된 열 속성은 수정하기
# 쿼리문
- 부서 테이블의 비고 column이 'active'인 데이터를 조회하는 쿼리(소문자 active만 검색)
# AS_IS
select 부서명, 비고
from 부서
where 비고 = 'active'
and ASCII(substr(비고,1,1)) = 97
and ASCII(substr(비고,2,1)) = 99
- 첫번째 문자의 ascii 코드값이 97(소문자 a) 이고 두번째 문자의 코드값이 99(c)인 대상만 출력
# Tuning
- 소문자 여부를 판단하려고 굳이 아스키코드를 비교해야 할 필요가 있을지에 대한 고민

- 우선, SQL의 조건절에서 ASCII조건을 빼고 수행해본 결과, 위처럼 대소문자가 섞인 상태인 데이터가 출력됨
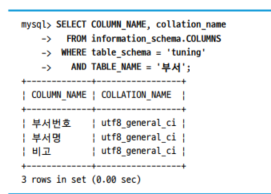
- 부서 테이블의 column들의 콜레이션 조회 시, UTF8_general_ci(대소문자 구분이 없는 utf8)임을 알 수 있음
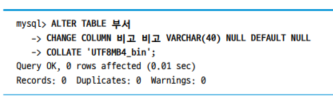
- 비고 column의 콜레이션을 emoji(이모지)까지 지원하는 UTF8MB4_bin으로 변경하면, substr(), ascii()함수가 수행하던 불필요한 작업을 제거할 수 있다.
# TO_BE
-- 0.000 sec / 0.000 sec
alter table 부서 change column 비고 비고 varchar(40) null default null collate 'UTF8MB4_bin';
select 부서명, 비고
from 부서
where 비고 = 'active'
2) 대소문자가 섞인 데이터를 자주 비교하는 경우, 대소문자 구분없는 콜레이션으로 열 추가해보기
# 쿼리문
- 사원테이블에서 입사일자가 1990년 이후이고 이름이 'MARY'인 사원정보를 조회하는 쿼리
- 이 때 영문의 대소문자는 고정되지 않음
# AS_IS
-- 0.328 sec / 0.000 sec
select 이름, 성, 성별, 생년월일
from 사원
where lower(이름) = lower('MARY')
and 입사일자 >= STR_TO_DATE('1990-01-01', '%Y-%m-%d')
- where 절에 이름 / 입사일자 column 조건이 있지만 table full scan을 수행함
# Tuning

- 조건절로 조회되는 데이터 건수 확인 시, 사원 테이블에 30만건정도 데이터가 있으며 그 중 입사일자 컬럼을 활용하는 조건문에 해당하는 데이터는 13만건이고 이름을 활용하는 조건문에 해당하는 데이터는 224건
- 즉, 입사일자 열의 조건문에는 전체 데이터 건수 대비 약 43%에 달하는 데이터가 있으므로 입사일자 열의 인덱스를 활용할 수 없다는 것을 예상할 수있다. 반면 함수에 의해 가공된 이름 조건절은 매우 적은 범위의 데이터에 접근할 수 있다.
- 인덱스 확인 시 입사일자 index만 존재하기 때문에 변별력있는 이름 column을 활용하여 index를 생성하는 것이 좋다.

- 사원 테이블의 콜레이션 조회 시, 이름 column의 콜레이션이 UTF8_bin(대소문자 구분 콜레이션)임을 알 수 있다. 해당 콜레이션은 데이터 정렬 및 비교 시 대소문자를 구분하여 처리한다.
- 최초 입력된 대소문자를 그대로 유지하려면 이름 콜레이션은 유지가 되어야 하지만, 이름 정보를 검색할 땐 대소문자 구분이 없어야 하므로, 강제적으로 LOWER()함수를 써야 하기 때문에 이름 INDEX를 생성하더라도 활용이 불가능할 것
=> 이름 열에 대해 대소문자 구분없이 비교 처리를 수행하는 별도의 COLUMN을 추가해볼 것
# TO_BE
- 소문자_이름 이라는 신규 컬럼을 추가하며, 신규 컬럼은 별도의 콜레이션을 명시하지 않는 한 테이블의 콜레이션값을 상속받으므로 utf8_general_ci로 설정된다.
- utf8_general_ci는 대소문자를 구분하지 않는 열이므로 lower()함수를 사용할 필요가 없다.
-- 0.063 sec / 0.000 sec
-- 소문자_이름 컬럼 생성
alter table 사원 add column 소문자_이름 varchar(14) not null after 이름;
update 사원
set 소문자_이름 = lower(이름);
-- 소문자_이름 index 생성
alter table 사원 add index I_소문자이름(소문자_이름);
select 이름, 성, 성별, 생년월일
from 사원
where 소문자_이름 = 'MARY'
and 입사일자 >= '1990-01-01'
- 'MARY'는 대소문자 구분없이 사용자가 입력한 값으로 판단됨
- 소문자_이름 index로 데이터를 조회
- 이름 데이터가 중복되므로 디스크 용량이 낭비되는 비효율적 방식처럼 보일 수 있지만, 인덱스를 활용하여 변별력이 좋은 열을 적절하게 사용하는 쿼리 튜닝 방법
3) 규모가 크고 고루 분포한 데이터의 경우, PARTITIONING을 활용해보기
# 쿼리문
- 급여 테이블에서 2000년의 데이터를 모두 집계하는 쿼리
# AS_IS
-- 0.000 sec / 0.000 sec
select count(1)
from 급여
where 시작일자 between str_to_date('2000-01-01', '%Y-%m-%d')
and str_to_date('2000-12-31', '%Y-%m-%d');
- I_사용여부 index를 사용해서 커버링 인덱스(테이블 접근 없이 인덱스만으로 원하는 데이터를 조회)로 수행
# Tuning
- 급여 테이블의 시작일 / 월 / 연 단위의 조회가 빈번히 발생한다고 가정하고 진행

- 급여 테이블의 전체 데이터가 약 2844047건에 비해, 해당 조건에 해당하는 결과는 255785건으로 전체의 9%수준
- 연도별 데이터 건수를 확인한 결과, 대부분 1986 ~ 20002년까지 고루 퍼져잇음을 알 수 있다.
- 이렇게 급여 테이블을 year(시작일자) 라는 column으로 논리적으로 분할하는 partitioning을 할 수 있다.
alter table 급여
partition by range columns(시작일자)
( partition p85 values less than ('1985-12-31'),
partition p86 values less than ('1986-12-31'),
partition p87 values less than ('1987-12-31'),
partition p88 values less than ('1988-12-31'),
partition p89 values less than ('1989-12-31'),
partition p90 values less than ('1990-12-31'),
partition p91 values less than ('1991-12-31'),
partition p92 values less than ('1992-12-31'),
partition p93 values less than ('1993-12-31'),
partition p94 values less than ('1994-12-31'),
partition p95 values less than ('1995-12-31'),
partition p96 values less than ('1996-12-31'),
partition p97 values less than ('1997-12-31'),
partition p98 values less than ('1998-12-31'),
partition p99 values less than ('1999-12-31'),
partition p00 values less than ('2000-12-31'),
partition p01 values less than ('2001-12-31'),
partition p02 values less than ('2002-12-31'),
partition p03 values less than (MAXVALUE) );
# TO_BE
-- 0.000 sec / 0.000 sec
select count(1)
from 급여
where 시작일자 between str_to_date('2000-01-01', '%Y-%m-%d')
and str_to_date('2000-12-31', '%Y-%m-%d');
- 범위 파티션을 설정하였기 때문에 시작일자 데이터가 2000년도인 파티션에만 접근
- 2000년도 데이터가 있는 p00 파티션에 접근한 뒤, 2000-12-31 시작일자의 다음 데이터도 2000년인지 확인하는 작업이 수행되므로 2001년 데이터까지 접근하므로 partitions 항목에 p00, p01이 출력됨
4. 정리
1. JOIN / 서브쿼리 변형하여 SQL문 재작성으로 착한 쿼리 만들기
- 처음부터 모든 데이터를 가져오지 않기
- 비효율적인 페이징을 수행하지 않도록 주의하기
- 필요 이상으로 많은 정보를 가져오지 않도록 하기
- 대량의 데이터를 가져와 조인하는 경우, 해당 조인이 반드시 필요한 조건인지 확인하기
2. 인덱스 조정으로 착한 쿼리 만들기
- 인덱스 없이 작은 규모의 데이터를 조회하지 않도록 하기
- 조건 절에 쓰이는 컬럼이 인덱스를 사용하도록 인덱스를 생성해보기
- 인덱스가 있는 컬럼에서 큰 규모의 데이터 변경 발생 시, 인덱스 삭제 고려하기
- 비효율적인 인덱스는 수정하기 (인덱스의 컬럼 순서 바꾸기)
3. 적절한 테이블 및 열 속성 설정으로 착한 쿼리 만들기
- 잘못된 열 속성은 수정하기
- 대소문자가 섞인 데이터를 자주 비교하는 경우, 대소문자 구분없는 콜레이션으로 열 추가해보기
- 규모가 크고 고루 분포한 데이터의 경우, PARTITIONING을 활용해보기
5. 출처
- 업무에 바로 쓰는 SQL 튜닝
'전공 > DB' 카테고리의 다른 글
| [CS면접 질문 정리] 데이터베이스 (0) | 2022.04.26 |
|---|---|
| [데이터베이스] 전공 필기 시험 정리 (0) | 2022.04.01 |
| MySQL튜닝5) 튜닝 기본 예제 (0) | 2022.02.08 |
| MySQL튜닝4) 실행계획 살펴보기2 (0) | 2022.01.26 |
| MySQL튜닝3) 실행계획 살펴보기1 (0) | 2022.01.19 |



