1. 실습 데이터 세팅
- 실습 데이터 URL : https://github.com/7ieon/SQLtune
- 실습 데이터 정보

2. SQL문 단순 수정으로 착한 쿼리 만들기
1) 사원번호가 1100으로 시작하면서 사원번호가 5자리인 사원 정보 출력
# AS_IS
-- 0.329 sec / 0.000 sec
SELECT *
FROM 사원
WHERE SUBSTRING(사원번호,1,4) = 1100
AND LENGTH(사원번호) = 5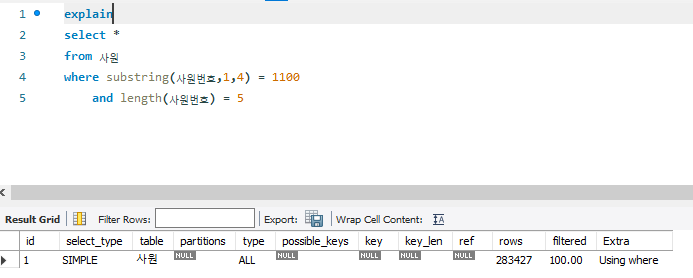
# Tuning
- 기본키인 사원번호 접근 시 WHERE 절에서 가공하여 접근
=> Table Full Scan이 발생 (type = 'ALL')
# TO_BE
-- 0.000 sec / 0.000 sec
SELECT *
FROM 사원
WHERE 사원번호 BETWEEN 11000 AND 11009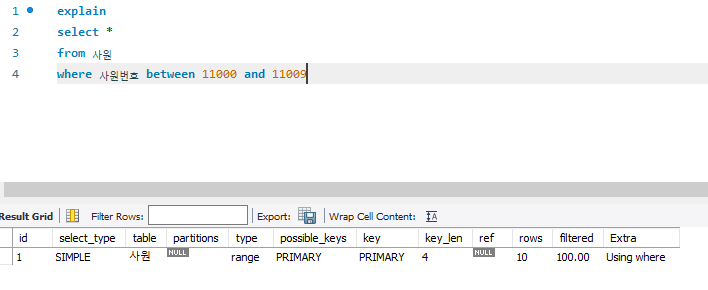
# Conculusion
- 기본키를 변형하지 않도록 한다.
2) 사원 테이블에서 성별 기준으로 몇 명의 사원이 있는지 출력하는 쿼리
# AS_IS
-- 1.187 sec / 0.000 sec
select IFNULL(성별,'NO DATA') AS 성별, COUNT(1) 건수
from 사원
group by IFNULL(성별, 'NO DATA')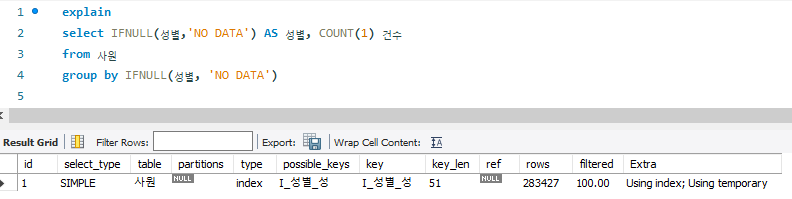
key 항목이 "I_성별_성" INDEX로 나타나므로 INDEX FULL SCAN으로 수행되었으며, Extra 방식이 "Using temporary"이므로 임시테이블을 생성
# Tuning
- 사원 테이블의 성별에는 NULL값이 존재하지 않고 M / F 만 저장됨
- 사원 테이블의 구조를 보면 성별은 NOT NULL 조건이 있음
=> 현재 IFNULL()함수를 처리하기 위해 DB 내부적으로 별도의 임시테이블을 만들면서 null여부를 검사하려 했지만, 이는 불필요한 함수이다.
# TO_BE
-- 0.250 sec / 0.000 sec
select 성별, COUNT(1) 건수
FROM 사원
GROUP BY 성별;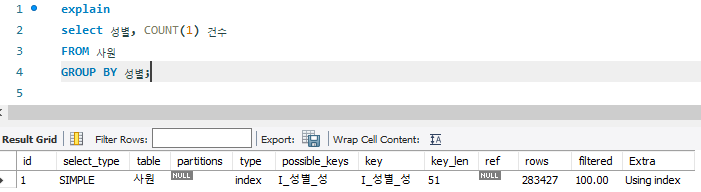
임시 테이블 없이 인덱스만 사용하여 데이터 추출
# Conculusion
- 쿼리 실행 시 불필요한 함수를 호출하지 않도록 한다.
(3) 급여 테이블에서 현재 유효한 급여 정보만 조회하고자, 사용여부 열의 값이 1인 데이터 출력하는 쿼리
#AS_IS
-- 1.000 sec / 0.000 sec
select count(1)
from 급여
where 사용여부 = 1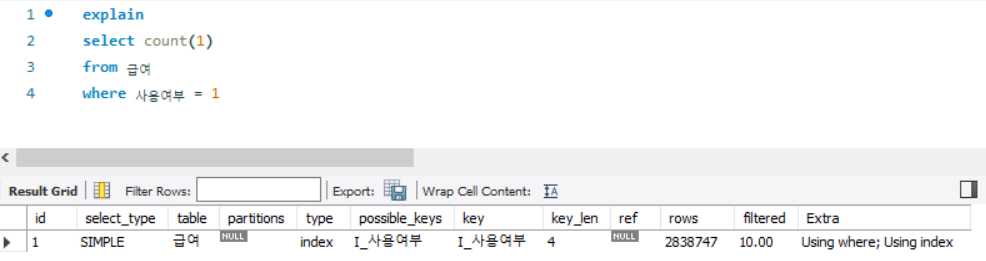
- key 항목이 I_사용여부 로 출력되므로 해당 인덱스를 사용
- type 항목이 index이므로 인덱스 풀 스캔으로 수행
- filtered 항목이 10.00이므로 MySQL 엔진으로 가져온 데이터 중 10%를 추출해서 최종 데이터를 출력함
# Tuning
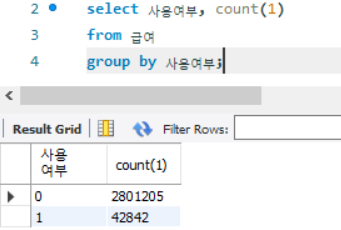
- 총 50만 건의 데이터가 있고, 사용 여부 열에는 0, 1, ' '데이터가 있음
- 사용여부 열 값이 '1'인 데이터는 전체 데이터 대비 10%이하
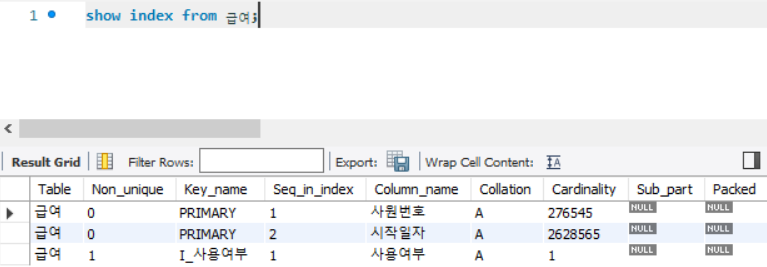
- 기본 키는 사원번호/시작일자 이며, I_사용여부 인덱스는 사용여부 열로 구성
=> 사용여부 열이 인덱스로 구성되었고, WHERE절의 조건문으로 작성되었음에도 실행계획에선 INDEX FULL SCAN으로 수행
=> 조건문 파악 필요
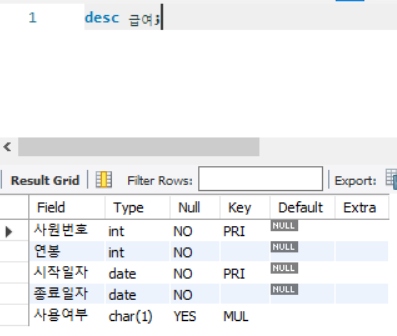
- 사용 여부 열은 문자형이 char(1)인 데이터 유형이지만, where 조건에선 숫자 유형으로 데이터에 접근
=> DBMS 내부의 묵시적 형변환 발생
=> 전체 데이터를 스캔하는 FULL SCAN 발생
# TO_BE
-- 0.031 sec / 0.000 sec
select count(1)
from 급여
where 사용여부 = '1';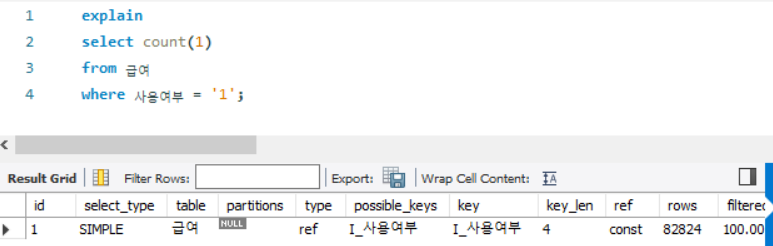
- key 항목에서 I_사용여부 인덱스를 사용하여 데이터 접근
- 사용여부 = '1' 조건 절이 스토리지 엔진에 전달되어 필요한 데이터만 가져옴
# Conculusion
- 형 변환으로 인덱스를 활용하지 못하는 예를 없애도록 한다.
(4) 사원 테이블에서 남자인 Radwan사원을 출력하는 쿼리
#AS_IS
-- 0.297 sec / 0.000 sec
select *
from 사원
where concat(성별,' ',성) = 'M Radwan';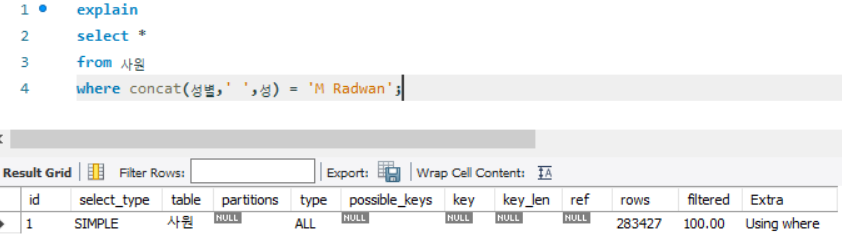
- 사원 테이블은 where 조건절(concat 함수 사용으로 데이터 변형)로 데이터에 접근
- type 항목이 ALL로 테이블 풀 스캔으로 접근(rows : 약 30만개)
# Tuning
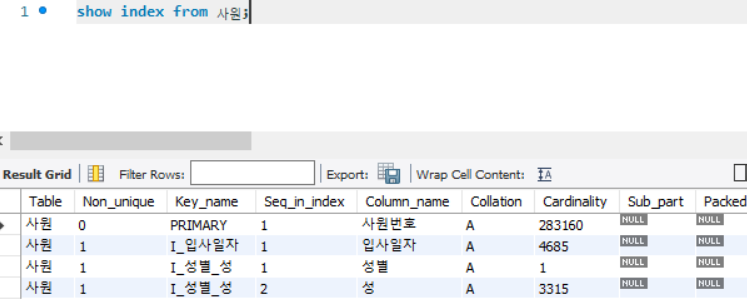
- 인덱스인 I_성별_성 인덱스를 사용할 수 있고, 조건문도 동등조건이므로, 인덱스를 활용하여 조회가 가능한 쿼리
# TO_BE
-- 0.031 sec / 0.000 sec
select *
from 사원
where 성별 = 'M' and 성 = 'Radwan'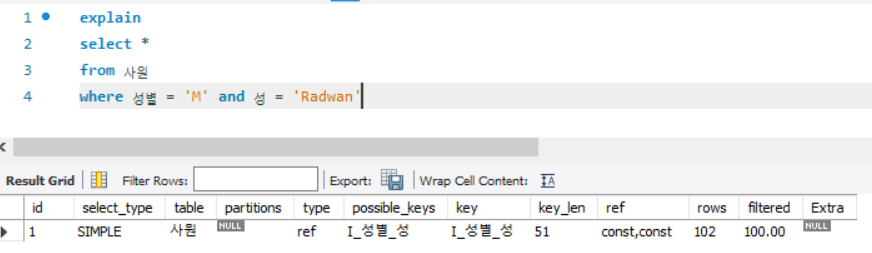
- 인덱스의 동등조건을 사용하였으므로 type 컬럼이 ref이다.
- rows는 102 건
# Conculusion
- 열을 결합하여 사용하지 않도록 한다.(결합하려는 열이 인덱스가 존재하는 경우)
(5) 부서 관리자의 사원번호 ,이름, 성, 부서번호 데이터를 중복 제거하여 조회하는 쿼리
# AS_IS
-- 0.000 sec / 0.000 sec
select distinct 사원.사원번호, 사원.이름, 사원.성, 부서관리자.부서번호
from 사원
join 부서관리자
on (사원.사원번호 = 부서관리자.사원번호)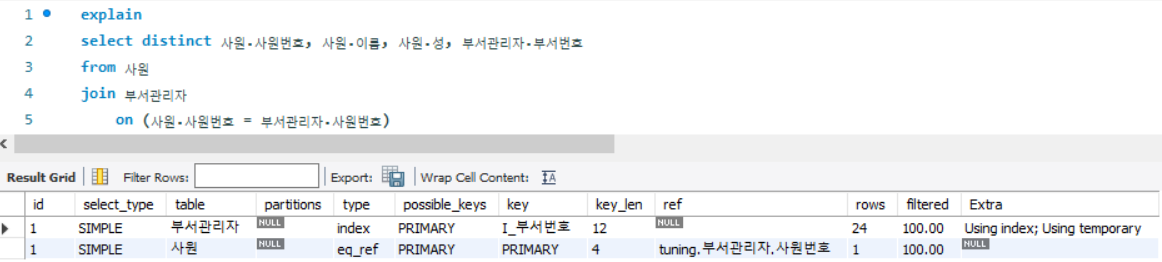
- 드라이빙 테이블 : 부서관리자 / 드리븐 테이블 : 사원
- 부서 관리자 테이블의 type : index ( index full scan 방식으로 수행됨)
- 사원 테이블의 type : eq_ref (사원번호라는 primary key를 사용하여 1건의 데이터를 조회하는 방식으로 조인됨)
- Extra : Using temporary (distinct를 수행하고자 별도의 임시테이블 생성)
# Tuning
- 사원 테이블의 primary key는 '사원번호'이므로, select 절의 사원.사원번호 에는 중복 데이터가 존재하지 않음
=> distinct 키워드로 정렬작업 후 중복 제거하는 작업은 불필요함
(참고 : distinct 키워드는 나열될 열들을 정렬한 뒤 중복 데이터는 삭제한다. 따라서 distinct를 쿼리에 작성하는 것만으로도 정렬 작업이 포함됨을 인지해야 함)
# TO_BE
-- 0.000 sec / 0.000 sec
select 사원.사원번호, 사원.이름, 사원.성, 부서관리자.부서번호
from 사원
join 부서관리자
on (사원.사원번호 = 부서관리자.사원번호)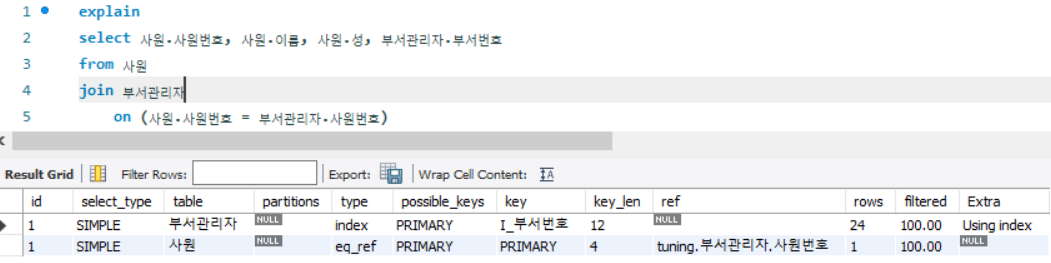
- Extra 항목의 Using temporary가 삭제됨 (불필요한 작업 제거)
# Conculusion
- 불필요한 distinct는 하지 않아야 한다.
(6) 성이 Baba인 사원 데이터를 남/ 녀 별로 나누어 union으로 조회하는 쿼리
# AS_IS
-- 0.000 sec / 0.000 sec
select 'M' as 성별, 사원번호
from 사원
where 성별 = 'M'
and 성 = 'Baba'
union
select 'F', 사원번호
from 사원
where 성별 = 'F'
and 성 = 'Baba'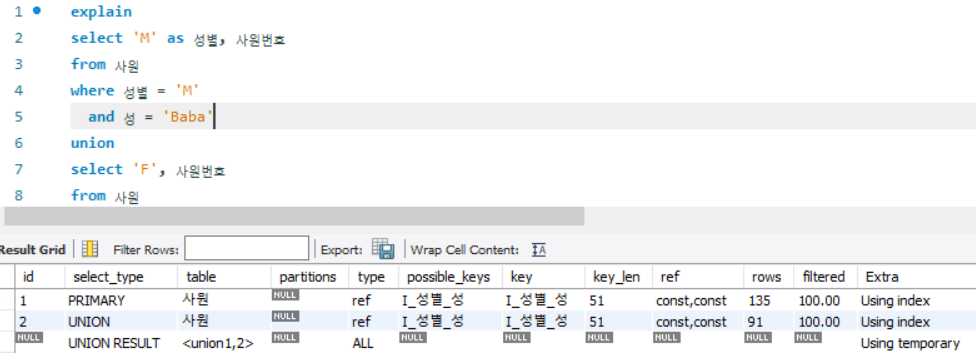
- id가 null인 행에서 id = 1인 행과 id = 2인 행의 결과를 통합하여 중복제거 하는 union 작업 수행
- 이 때, 임시 테이블을 생성하게 됨. 만약 메모리에 상주하기 어려울 만큼 id = 1,2의 결과량이 많다면 메모리가 아닌 임시 파일을 생성할 수 도 있다.
# Tuning
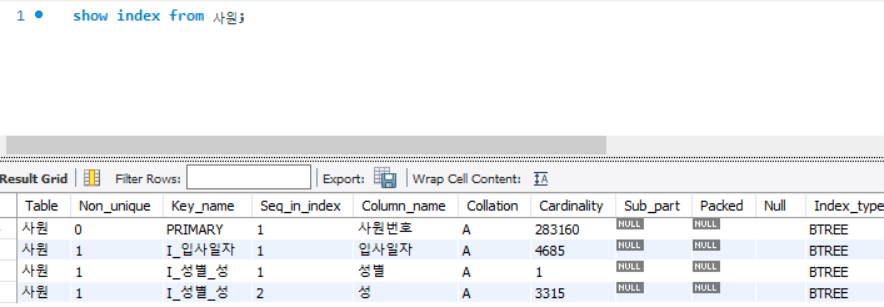
- where 절의 성별 / 성 컬럼이 동등 조건으로 작성되어 있으므로, I_성별_성 index로 빠르게 조회 가능
- 또한 union 연산으로 통합하는 과정에서 두 결과를 합친 후 중복제거를 하지만 이미 사원번호라는 기본키가 출력되는 SQL문에서 중복제거는 불필요
# TO_BE
-- 0.000 sec / 0.000 sec
select 'M' as 성별, 사원번호
from 사원
where 성별 = 'M'
and 성 = 'Baba'
union all
select 'F', 사원번호
from 사원
where 성별 = 'F'
and 성 = 'Baba'
- 정렬 및 중복 제거 작업이 없어짐 (AS_IS의 3번째 행이 없어짐)
# Conculusion
- 불필요한 union(중복제거)처리는 하지 않는다.
(7) 성과 성별로 grouping하는 쿼리
# AS_IS
-- 0.016 sec / 0.062 sec
select 성, 성별, count(1) as 카운트
from 사원
group by 성, 성별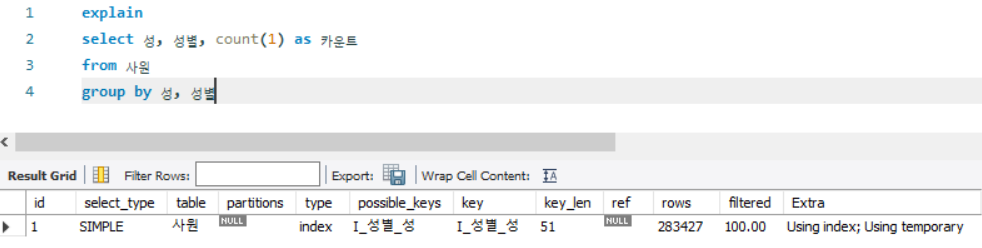
- I_성별_성 index를 사용하고, 임시테이블을 생성하여 성 / 성별을 grouping 해 count() 연산 수행
- I_성별_성 index의 구성 열이 group by 절에 포함되므로, 테이블 접근 없이 인덱스만 사용하는 커버링 인덱스(Using Index)로 수행
# Tuning
- 인덱스를 활용하는데도 메모리나 디스크에 임시테이블을 꼭 생성해야 하는지에 대한 고민이 필요 (인덱스만으로 count연산을 수행할 수 있다면 임시테이블은 필요가 없을 것)
=> I_성별_성 index는 성별 컬럼 기준으로 정렬 후 성 컬럼으로 정렬되었다는 의미이므로, 인덱스 순서 활용 가능
# TO_BE
-- 0.109 sec / 0.219 sec
-- 인덱스 순서대로 grouping
select 성, 성별, count(1) as 카운트
from 사원
group by 성별, 성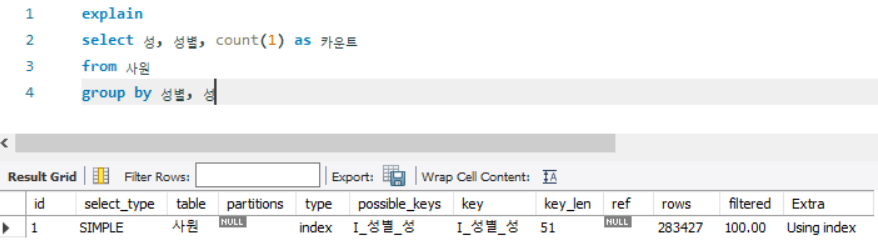
# Conculusion
- 인덱스의 열을 고려하여 정렬 작업을 수행해야 한다.
(8) 입사일자가 '1989'로 시작하면서 사원번호가 100,000을 초과하는 데이터를 조회하는 쿼리
# AS_IS
-- 0.031 sec / 0.265 sec
select 사원번호
from 사원
where 입사일자 LIKE '1989%'
and 사원번호 > 100000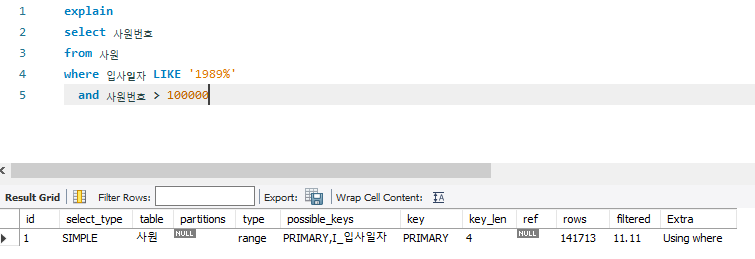
- 사원 번호인 primary key로 index range scan 실행
- 스토리지 엔진으로부터 기본 키를 구성하는 사원번호를 조건으로 데이터를 가져온 뒤, MySQL 엔진에서 남은 필터 조건(입사일자 like '1989%')으로 추출하기 때문에 filtered가 11.11%가 나옴
# Tuning

- 전체 데이터 개수는 약 30만개
- 입사일자 like '1918%'을 만족하는 데이터 개수는 28394개
- 사원번호 > 100000 인 데이터 개수는 약 20만개
=> 사원번호가 100000을 초과하는 데이터의 비율이 전체 데이터의 70%를 차지하므로, 스토리지 엔진에서 데이터 접근 시 기본키(사원번호)로 접근하는 것이 효율적이지 않을 수 있음
=> 한편, 입사일자가 1989%인 사원 수는 전체 데이터 대비 10%이므로, 입사일자 열을 데이터 엑세스 조건으로 활용 검토
# TO_BE
-- 0.016 sec / 0.062 sec
select 사원번호
from 사원
where 입사일자 >= '1989-01-01'and 입사일자 < '1990-01-01'
and 사원번호 > 100000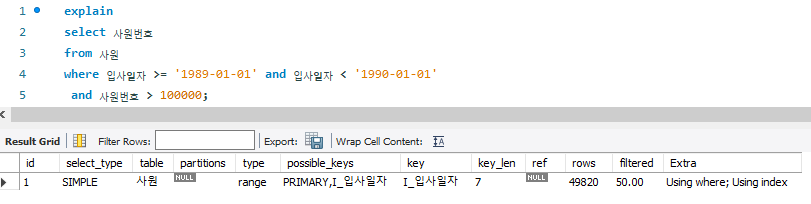
-입사일자 컬럼의 데이터 유형이 date이고, LIKE 절보다 부등호(< > <= >=) 절이 우선하여 인덱스를 사용하므로, 데이터 접근 범위를 줄임
- I_입사일자 index를 활용하여 index range scan을 수행
- 테이블에 직접 접근하지 않고 I_입사일자 index만 사용하여 최종 결과를 출력 (커버링 인덱스 스캔, extra 항목의 Using index라고 함)
# Conculusion
- 더 효율적인 인덱스를 사용할 수 있는지에 대한 검토가 필요하다.
(9) B출입문으로 출입한 이력이 있는 정보를 조회하는 쿼리
# AS_IS
-- 0.016 sec / 1.875 sec
select *
from 사원출입기록
where 출입문 = 'B';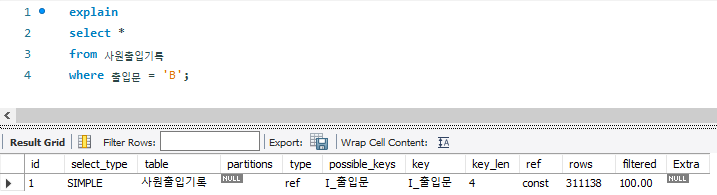
# Tuning

- 사원출입기록 테이블 중 출입문 B는 총 66만건 데이터 중 30만건을 차지하므로 전체 데이터의 50%
=> 앞의 실행계획에 따르면 I_출입문 index로 index scan을 수행하는데, 전체 데이터의 약 50%에 달하는 데이터를 조회하기 위해 인덱스를 활용하는 것은 효율적이지 않을 수 있다.
# TO_BE
-- 0.297 sec / 0.656 sec
select *
from 사원출입기록 ignore index(I_출입문)
where 출입문 = 'B';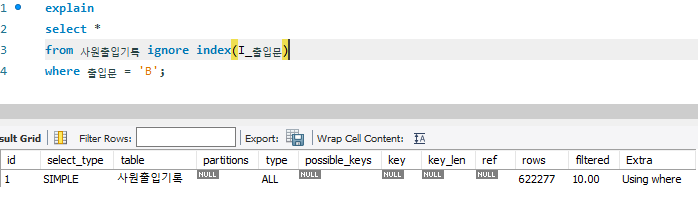
- 인덱스를 무시할 수 있도록 IGNORE INDEX라는 힌트 사용
- 랜덤 엑세스가 발생하지 않고, 한번에 다수의 페이지에 접근하는 테이블 풀 스캔 방식으로 수행되므로 더 효율적으로 실행
# Conculusion
- 전체 데이터 대비 조회 결과 데이터 비율이 높다면, 인덱스를 활용하지 않는 편이 좋을 수 있다.
(10) 입사일자가 1994년 1월1일부터 2000년 12월 31일까지인 사원들의 이름과 성을 출력하는 쿼리
# AS_IS
-- 0.141 sec / 1.188 sec
select 이름, 성
from 사원
where 입사일자 between STR_TO_DATE ('1994-01-01', '%Y-%m-%d')
and STR_TO_DATE ('2000-12-31', '%Y-%m-%d')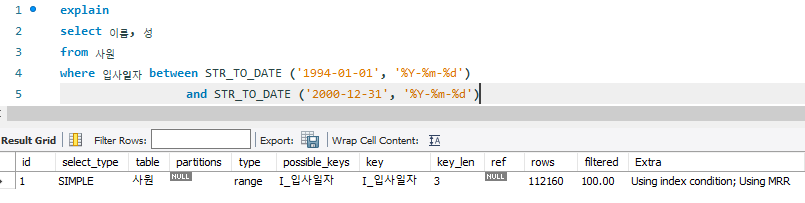
- 사원 테이블에서 I_입사일자 index로 range scan 수행
- Extra의 Using index condition : 스토리지 엔진에서 입사일자 조건절로 인덱스 스캔을 수행
- Extra의 Using MRR : 인덱스가 랜덤 액세스가 아닌 순차 스캔으로 처리
# Tuning
- 사원 테이블 데이터는 총 30만건인데 결과값은 4만건으로, 인덱스 스캔으로 랜덤 엑세스 부하 발생
- 입사일자 열 기준으로 매 번 1994~2000년의 데이터를 조회하는 경우가 잦다면, 랜덤 액세스의 부하가 발생하도록 하기보단 테이블 풀 스캔 방식으로 설정하는 것이 효율적일 수 있음
# TO_BE
-- 0.015 sec / 0.000 sec
select 이름, 성
from 사원
where year(입사일자) between '1994' and '2000'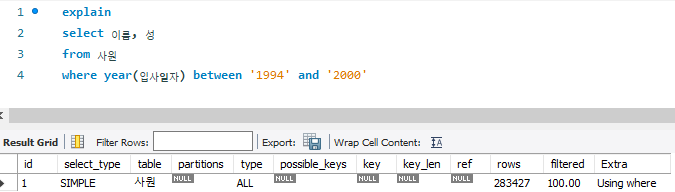
- 인덱스 없이 테이블에 직접 접근하며 한 번에 다수의 페이지에 접근하므로 더 효율적
# Conculusion
- 인덱스 스캔으로 잦은 랜덤 엑세스 부하 발생한다면 인덱스를 활용하지 않는 편이 좋을 수 있다.
3. 테이블 조인 설정 변경으로 SQL 튜닝하기
(1) 부서의 시작일자가 '2002-03-01'이후인 사원 데이터를 조회하는 쿼리
# AS_IS
-- 5.266 sec / 2.031 sec
select 매핑.사원번호,
부서.부서번호
from 부서사원_매핑 매핑,
부서
where 매핑.부서번호 = 부서.부서번호
and 매핑.시작일자 >= '2002-03-01';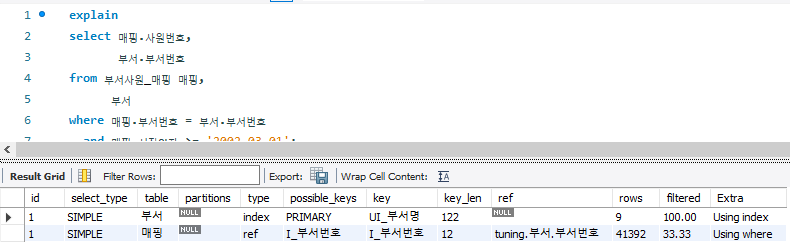
- 부서 테이블에 먼저 접근 후 UI_부서명 index를 활용해 index full scan
- 상대적으로 큰 크기의 부서사원매핑 테이블은 I_부서번호 index로 index scan 수행( 4만건의 행을 인덱스 스캔을 하고 랜덤 엑세스로 테이블에 접근)
# Tuning
- 위의 실행 예시처럼 드리븐 테이블에서 대량 데이터에 랜덤 액세스시 비효율적
- 부서사원_매핑 테이블에 30만 건 이상의 데이터를 MySQL 엔진으로 가져온 모든 데이터에 대해 where 절의 필터 조건(매핑.시작일자) 수행하기 때문에 매핑.시작일자 조건절을 먼저 적용할 수 있다면 조인 시 비교 대상 줄어듬
# TO_BE
-- 0.328 sec / 0.062 sec
select straight_join
매핑.사원번호,
부서.부서번호
from 부서사원_매핑 매핑,
부서
where 매핑.부서번호 = 부서.부서번호
and 매핑.시작일자 >= '2002-03-01';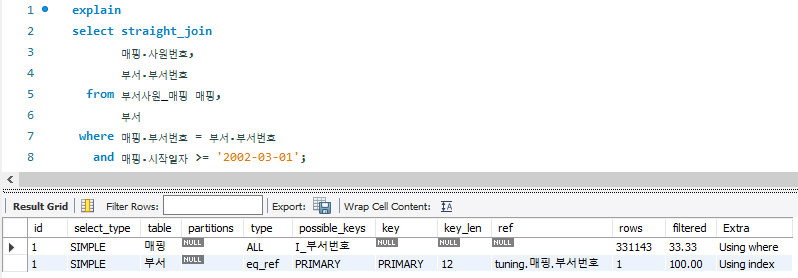
- straight_join 힌트를 사용하여, from절에 작성된 테이블 순서대로 조인에 참여할 수 있도록 고정
- 대용량인 부서사원_매핑 테이블을 먼저 접근하여 테이블 풀 스캔으로 한번에 다수 페이지 접근 후, 부서 테이블에선 primary key로 1개 데이터에 접근하는 방식
# Conculusion
- 작은 테이블이 먼저 조인에 참여하지 않도록 한다.
(2) 사원번호가 450,000 보다 크고 그동안 받은 연봉 중 한번이라도 100,000 달러를 초과한 적이 있는 사원 정보를 찾는 쿼리
# AS_IS
-- 0.172 sec / 0.516 sec
select 사원.사원번호, 사원.이름, 사원.성
from 사원
where 사원번호 > 450000
and (select max(연봉)
from 급여
where 사원번호 = 사원.사원번호) > 100000;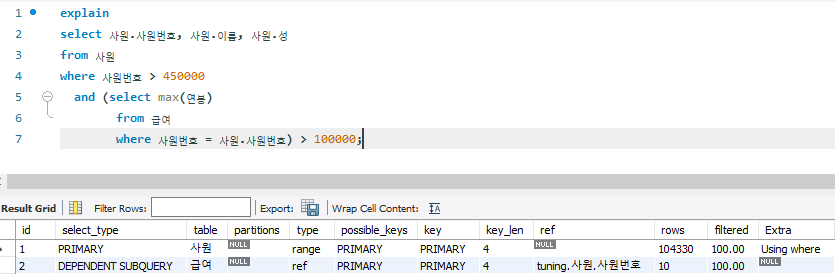
- 사원테이블은 primary key를 활용해서 index range scan 수행, 그 후 급여 테이블은 외부 테이블인 사원테이블로부터 조건을 전달받아 수행하는 의존 서브 쿼리(dependent subquery)로 수행
# Tuning
- select_type 항목에 DEPENDENT 키워드가 있으면, 외부 테이블에서 조건절을 받은 뒤 처리되어야 하므로 튜닝 대상으로 고려
- 외부 테이블인 사원 테이블의 사원 정보를 서브쿼리 대신 조인으로 변경
# TO_BE
-- 0.156 sec / 0.516 sec
select 사원.사원번호,
사원.이름,
사원.성
from 사원,
급여
where 사원.사원번호 > 450000
and 사원.사원번호 = 급여.사원번호
group by 사원.사원번호
having max(급여.연봉) > 100000;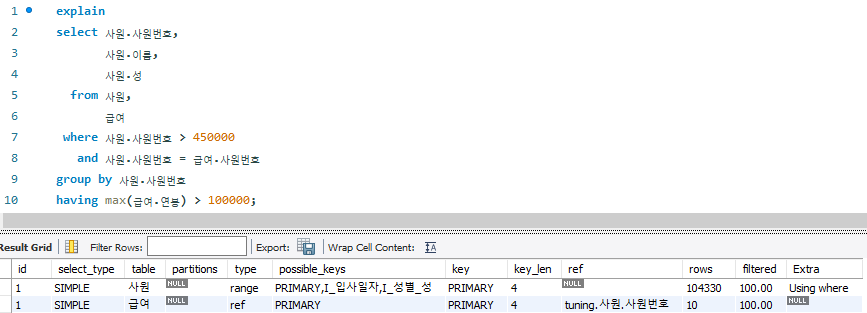
- 드라이빙 테이블은 급여 테이블, 드리븐 테이블은 사원 테이블
- 급여 테이블에 먼저 접근하기 위한 범위 축소 조건은 사원.사원번호 > 450000 절을 통해 급여.사원번호 > 450000 조건절로 변형되어 적용
- DEPENDENT 방식은 삭제되고, 사원 테이블과 급여 테이블이 조인하는 방식으로 변경
# Conculusion
- 메인 테이블에 의존하는 DEPENDENT 쿼리 방식은 사용하지 않도록 한다.
(3) A 출입문으로 출입한 사원이 총 몇명인지 구하는 쿼리
# AS_IS
-- 30.594 sec / 0.000 sec
select count(distinct 사원.사원번호) as 데이터 건수
from 사원,
( select 사원번호
from 사원출입기록 기록
where 출입문 = 'A') 기록
where 사원.사원번호 = 기록.사원번호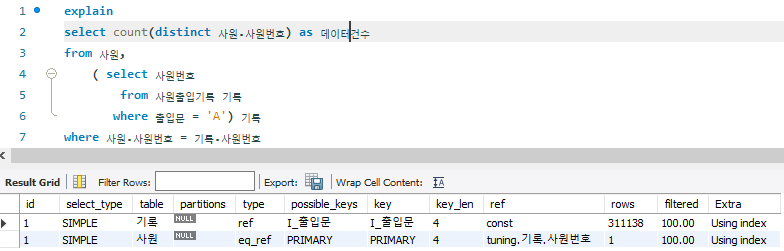
- 사원출입기록 테이블은 값이 'A'인 상수와 직접 비교하므로 ref 항목이 const, 인덱스를 사용한 동등 비교 수행하므로 type 항목이 ref로 표시
- 사원 테이블은 primary key를 사용해서 조인 조건절인 사원번호 컬럼으로 데이터 비교하기 때문에 type 항목에 eq_ref로 표시
# Tuning
select count(distinct 기록.사원번호) as 데이터건수
from 사원,
사원출입기록 기록
where 사원.사원번호 = 기록.사원번호
and 출입문 = 'A';- from 절의 인라인 뷰는 옵티마이저에 의해 view merging으로 최적화 되어 위의 SQL문처럼 수행됨
- select 절의 최종 결과는 사원번호에서 중복을 제거한 건수만 알면 됨
=> 사원출입기록의 사원번호는 중복제거를 하기 보단 사원 테이블과 조인 과정 중 값의 존재 여부만 확인해도 됨
=> EXISTS 사용 가능
# TO_BE
-- 0.641 sec / 0.000 sec
select count(1) as 데이터건수
from 사원
where exists ( select 1
from 사원출입기록 기록
where 출입문 = 'A'
and 기록.사원번호 = 사원.사원번호)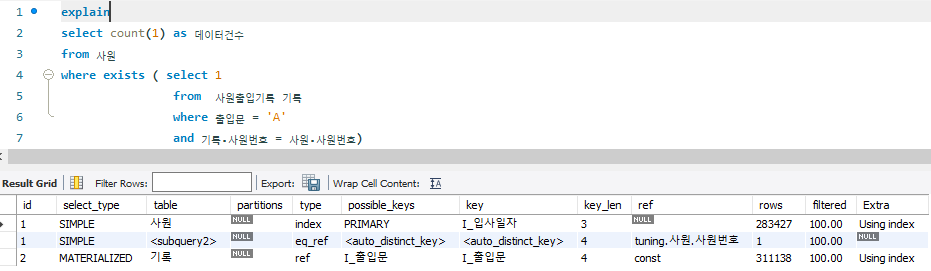
- 사원출입기록 테이블의 데이터는 최종결과에 사용하지 않고 존재 여부만 파악하면 되므로 EXISTS 구문으로 변경
- 실행계획을 보면, id가 1인 사원 테이블은 드라이빙 테이블이고, <subquery2>는 id = 2인 사원출력기록 테이블
- 사원출력기록 테이블은 EXISTS 연산자로 데이터 존재 여부를 파악하기 위해 임시 테이블을 생성하는 MATERIALIZED로 표기
# Conculusion
- 불필요한 조인을 수행하면 안된다.
4. 정리
1. SQL문 단순 수정으로 튜닝하기
- 기본키를 변형하지 않도록 한다.
- 쿼리 실행 시 불필요한 함수를 호출하지 않도록 한다.
- 형 변환으로 인덱스를 활용하지 못하는 예를 없애도록 한다.
- 열을 결합하여 사용하지 않는것이 좋다.(결합하려는 열이 인덱스가 존재하는 경우)
- 불필요한 distinct는 하지 않아야 한다.
- 불필요한 union(중복제거)처리는 하지 않는다.
- 인덱스의 열을 고려하여 정렬 작업을 수행해야 한다.
- 더 효율적인 인덱스를 사용할 수 있는지에 대한 검토가 필요하다.
- 전체 데이터 대비 조회 결과 데이터 비율이 높다면, 인덱스를 활용하지 않는 편이 좋을 수 있다.
- 인덱스 스캔으로 잦은 랜덤 엑세스 부하 발생한다면 인덱스를 활용하지 않는 편이 좋을 수 있다.
2. 테이블 조인 설정 변경으로 SQL 튜닝하기
- 작은 테이블이 먼저 조인에 참여하지 않도록 한다.
- 메인 테이블에 의존하는 DEPENDENT 쿼리 방식은 사용하지 않도록 한다.
- 불필요한 조인을 수행하면 안된다.
5. 출처
- 업무에 바로 쓰는 SQL 튜닝
'전공 > DB' 카테고리의 다른 글
| [데이터베이스] 전공 필기 시험 정리 (0) | 2022.04.01 |
|---|---|
| MySQL튜닝6) 튜닝 심화 예제 (0) | 2022.02.16 |
| MySQL튜닝4) 실행계획 살펴보기2 (0) | 2022.01.26 |
| MySQL튜닝3) 실행계획 살펴보기1 (0) | 2022.01.19 |
| MySQL튜닝2) SQL 튜닝 용어 이해하기2 (0) | 2022.01.12 |



