✔️ 테스트 기법
1. 블랙 박스 테스트(Back box test)
- 어떤 소프트웨어를 내부 구조나 작동 원리를 모르는 상태에서 소프트웨어의 동작을 검사하는 방법
- 필요한 것은 특징, 요구 사항, 검사를 위해 공개된 설계도 등 대외적으로 공개된 사항들이며 '이 소프트웨어는 무슨 역할을 수행해야 되는가'와 같이 대상이 되는 소프트웨어의 특징이나 요구 사항 등에 초점을 맞춰 검사가 이루어진다.
- 동등분할, 경계값 분석, 의사결정 테이블, 상태전이, 분류트리, 페어와이즈 조합
▶ 동등분할 기법(Equivalence Class Partitioning)
- 대표값을 이용하여 테스트 케이스를 도출
- 프로그램의 입력 도메인을 테스트 케이스가 산출 될 수 있는 데이터의 클래스로 분류하는 방법, 다양한 입력조건들을 갖춘 시험사례 유형들을 분할 : 상식적 경험에 의존(heuristic)
- 각 시험사례 유형마다 최소의 시험사례 작성
▶ 경계값분석기법(Boundary Value Analysis)
- 입력조건의 중간값에서 보다 경계값에서 에러가 발생될 확률이 높다는 점을 이용하여 이를 실행하는 테스트 케이스를 만드는 방법
▶ 의사결정 테이블(Decision Table Testing)
- 조건에 따라 참/ 거짓으로 표현
- 명세서가 논리적인 관계를 가지고 있는 경우, 대상을 조건과 결과로 구분하여 조합 관계를 고려한 테스트 방법
- 주요 의사 결정 요소들을 표로 만들고 요소들 간의 결합에 의한 테케 설계, 결정요소 조합을 통해 테스트 시나리오 도출
▶상태전이(State transition Testing)
- 상태 전이 다이어그램 기반으로 시스템 동작을 확인하는 기법
- 상태, 전이, 이벤트, 가드, 액션 사이의 관계를 검증하는 기법
- 상태 : 하나 이상의 이벤트를 기다리는 시스템 모드
- 전이 : 이벤트에 의해 한가지 상태에서 다른 상태로의 변경
- 이벤트 : 상태의 전이를 유발하는 요일
- 가드 : 이벤트가 발생하는 조건
- 액션 : 상태전이에 따라서 유발되는 동작
▶ 유즈케이스(usecase Teseting)
- USe Case 명세서를 이용한 테스트 케이스 설계
- 개발 초기부터 테스트 케이스 작성 가능
▶ 오류예측기법
- 각 시험기법들이 놓치기 쉬운 오류들을 감각 및 경험으로 찾아보는 것
▶ 원인-결과 그래프 기법
- 입력 데이터간의 관계가 출력에 미치는 영향을 그래프로 표현하여 오류 등을 발견하는 방법
▶ 페어 와이즈 조합 테스트
- 모든 가능한 입력 값들의 조합들을 테스트하는 대신에 모든 쌍(Pair)의 조합을 테스트하는 방법
- 조합 테스트 기법으로 조합의 개수를 보장성 있게 부여
2. 화이트박스 테스트(White-box-test)
소프트웨어 내부 소스 코드를 테스트 하는 기법
블랙박스 검사 기법은 소프트웨어의 내부를 보지 않고, 입력과 출력값을 확인하여 기능의 유효성을 판단하는 테스트 기법이며, 화이트 박스 검사 기법은 소프트웨어 내부 소스코드를 확인하는 기법이다.
코드가 어떤경로로 실행되며, 불필요한 코드 혹은 테스트 되지 못한 부분을 살펴 볼 수 있다.
화이트박스 테스트를 하는 부분은 대게 코드의 실행 경로를 확인해야 하기 때문에 시중에 나와 있는 커버리지 분석도구를 많이 활용한다.
화이트박스 검사 기법은 블랙박스 검사 기법에 비해 많은 시간과 분석을 필요로 하지만 오류가 발생되는 결함의 위치 등을 파악하는데 매우 유용하게 사용 할 수 있다.
제어흐름 그래프 테스트
- 프로그램의 제어구조를 그래프 형태로 나타내고 그래프 구성요소는 블록과 분기로 나타낼 수 있다.
데이터(자료) 흐름 테스트
- 제어흐름 그래프에 데이터 사용현황을 추가한 그래프
경로 테스트
- 테스트 커버리지를 달성하기 위한 entry/exit path를 선택하는 것
✔️ 일정 관리 방법론
1.PERT(Program-Evaluation and Review Technique)
1) PERT 특징
- 프로그램 평가 및 검토 기술이다.
- 과거에 경험이 없어서 소요 기간의 예측이 어려운 경우에 유리하다.
- 작업별로 낙관치, 기대치, 비관치로 나누어 종료 시기를 결정한다.
- 노드에는 작업명, 간선에는 낙관치, 기대치, 비관치를 표시한다.
- 간트 차트를 이용하여 이정표를 작성한다.
- 예측치 공식을 이용하여 소요 기간을 정한다.


- 일정이 가장 늦은 경로인 임계 경로는 A -> D -> E -> F -> G 이다.
퍼트 차트 용어
-
- ES(Earlist Start Time): 해당 단위 작업이 가장 빨리 시작할 수 있는 일자
- EF(Earlist Finish)
- LS(Latest Start): 가장 늦게 시작하는 일자 (작업을 망치지 않는 한도 내에서 얼마나 늦게 시작할 수 있나)
- LF(Latest Finish)
- Du(Duration): ES
EF, LSLF 작업 기간 - FT(Float Time): LS~ES 사이의 여유 기간
2. CPM(Critical Path Method)

- 임계 경로 기법이라고도 한다.
- 소요 기간이 확실한 경우에 유리하다.
- 노드는 작업명, 간선은 작업 사이의 전후 의존 관계를 표시한다.
- 원형 노드와 박스 노드로 구분된다.
- 원형 노드는 작업명, 박스 노드는 이정표를 표시하고, 예상 완료 시간을 표시한다.
- 한 이정표에서 다른 이정표에 도달하기 전에 작업을 완료해야 한다.
- 일정이 가장 늦은 경로인 임계 경로는 A -> D -> F -> H ->I이다.
- F작업은 E작업이 완료될 때까지 3일간의 여유 기간(Slack Time)이 존재한다.
3. WBS
- 프로젝트를 탑다운 방식으로 세분화하여 프로젝트의 단위 작업에 대해 파악하는 기법
- 프로젝트 팀이 수행할 작업을 인도물 중심으로 분할한 계층 구조 체계
- 프로젝트의 전체 범위를 산출물 중심의 트리 구조로 나타냄, 아래로 갈수록 작업들이 점차적으로 상세히 정의
요구 사항 분석
1. CASE(Computer Aided Software Engineering-자동화 도구)
1) CASE란
- 소프트웨어의 생명주기 전반을 지원하는 프로그램 또는 소프트웨어 개발을 지원하는 자동화도구 혹은 방법론의 결합
- 요구사항을 자동으로 분석하고 요구사항 분석 명세서를 기술하도록 개발된 도구(SADT, SREM, PSL/PSA, TAGS, EPOS)
- 이점: 문서화 품질 개선/분석자들 간의 적절한 조정/결함발견용이성/변경추적용이성/유지보수 비용 축소
* 프로그램을 만들어서 팔려고 하는데 그 프로그램을 짜는 형태를 지원해주는 노하우나 프로그램
2) CASE 예시
TAGS(Technology for Automated Generation of Systems)
- 시스템 공학 방법 응용에 대한 자동 접근 방법으로 개발 주기의 전 과정에 이용할 수 있는 통합 자동화 도구
- IORL : 요구사항 명세 언어
SADT(Structured Analysis and Design Technique)
- SoftTech 사에서 개발, 구조적 분석 및 설계 도구
- 블록 다이어그램을 채택한 자동화 도구
SREM(Software Requirements Engineering Methodology) -RSL/REVS
- TRW 사에서 개발, RSL과 REVS를 사용하는 요구 분석용 자동화 도구
- RSL(Requirement Statement Language) : 요소,속성,관계,구조들을 기술하는 요구사항 기술언어
- REVS(Requirement Engineering and Validation System) : RSL 기술 요구사항 분석 명세서를 출력하는 분석기
PSL/PSA
- 미시간대학에서 개발, PSL과 PSA를 사용하는 요구 분석용 자동화 도구
- PSL(Problem Statement Language) : 요구사항 기술언어
- PSA(Problem Statement Anayzer) : PSL 기술 요구사항 분석 명세서를 출력하는 문제(요구사항) 분석
3) CASE의 특징
- CASE 툴의 가격은 비싸지만 개발 비용은 절감된다.
- 스스로 동작하는 것이 아니라 명령어나 문법이 필요하다 (ex. 엑셀)
- 수정이 용이하며 정확함 (ex. 유저의 이름을 고양이에서 강아지로 변경)
- 개발 기간이 단축됨 (ex. 필기 < 타이핑)
- 생산성, 재사용성, 품질이 좋아짐 (ex. 하나하나 쓰기 < 복붙)
- CASE 툴 간의 호환성이 없고, 필요도 없음 (ex. MS word 문서를 - 아래한글로와 같은 호환성)
4) CASE의 분류
- 상위(Upper) CASE : 요구 분석과 설계 지원
- 하위(Lower) CASE : 코드작성(구현), 검사(테스트) 지원
- 통합(Total) CASE: 개발 주기 전 과정 지원
2. 요구사항 분석 HIPO(Hierarchy Input Process Output)
1) 설명
- 기본 시스템 모델은 입력, 처리, 출력으로 구성되며, 하향식 소프트웨어 개발을 위한 문서화 도구다.
- 체계적인 문서 관리 가능
- 기호,도표 등을 사용해서 보기가 쉽고 이해도 쉽다.
- 기능과 자료의 의존 관계를 동시에 표현할 수 있다.
- 변경, 유지보수 용이
- 시스템의 기능을 고유 모듈들로 분할하여 이들 간의 인터페이스를 계층구조로 표현한 것을 HIPO Chart라고 한다.
2) 도표
가시적 도표(도식 목차,Visual Table of Contents)
- 시스템의 전체적 기능과 흐름을 보여주는 계층(Tree) 구조도.

총체적 도표(총괄개요 도표, Overview Diagram)
- 프로그램을 구성하는 기능을 기술한 것으로 입력,처리,출력에 대한 전반적 정보를 제공하는 도표
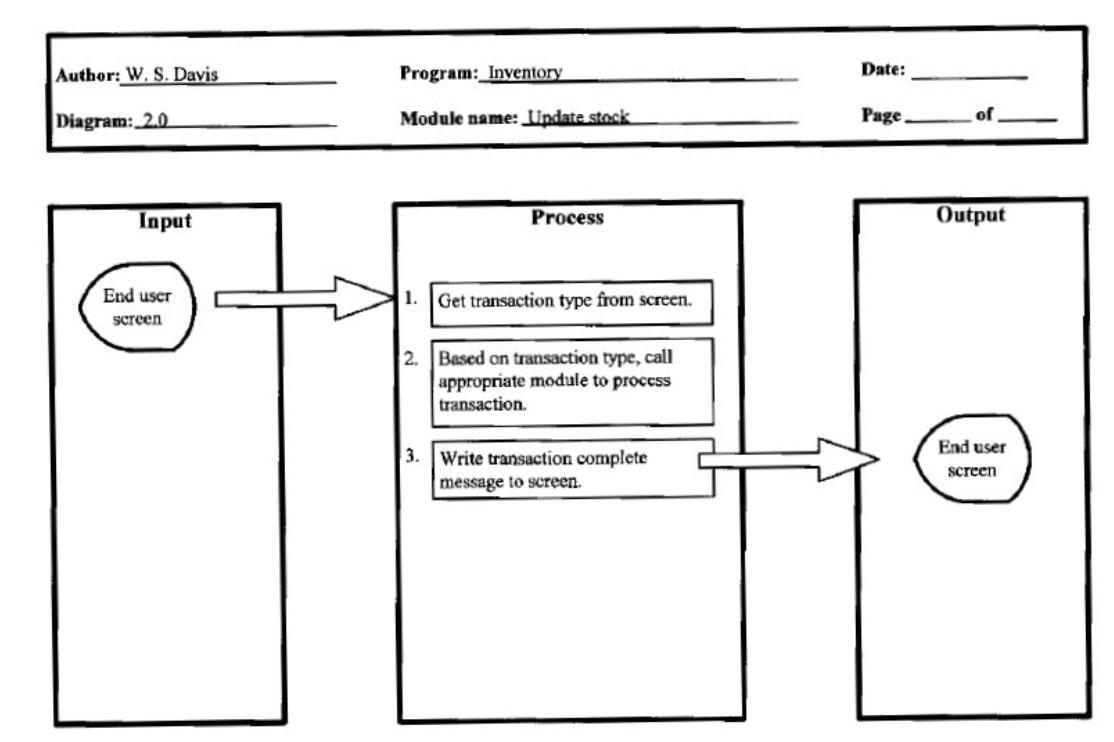
세부적 도표(상세 도표, Detail Diagram)
- 총체적 도표에 표시된 기능을 구성하는 기본 요소들을 상세히 기술하는 도표
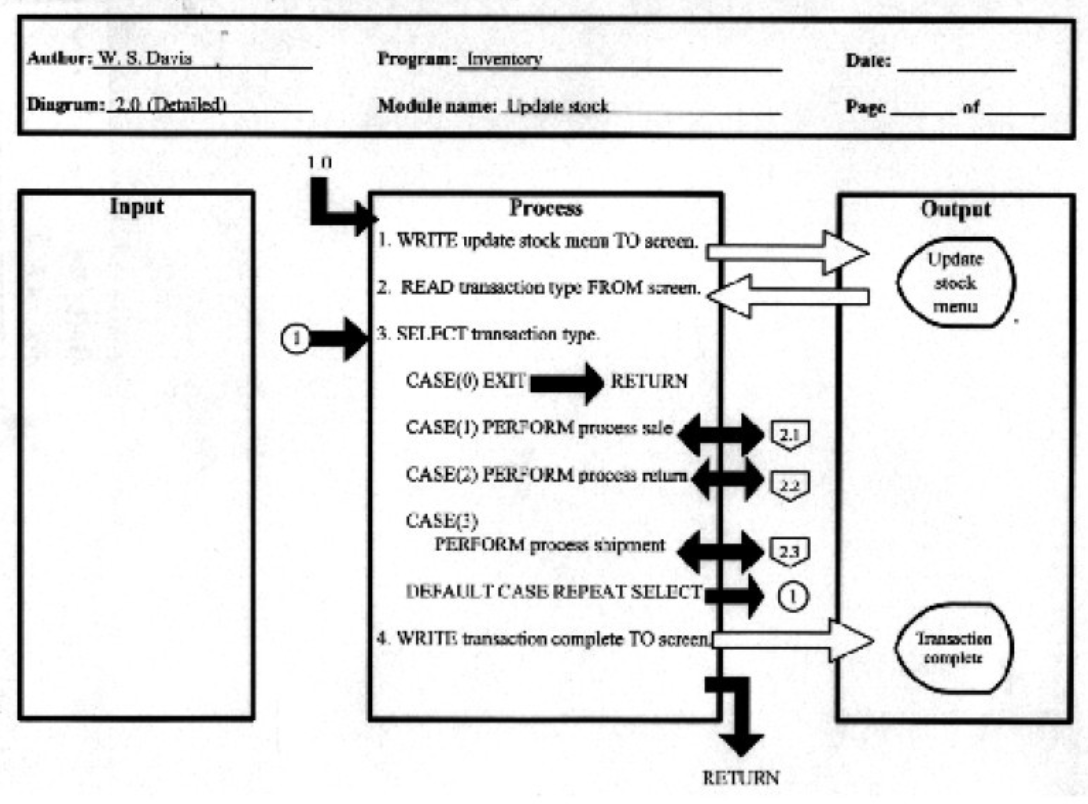
✔️ 비용 산정 기법
1. 하향식 비용 산정 기법(top-down)
과거 유사 경험을 바탕으로 회의를 통해 산정하는 비과학적인 기법
- 전문가 감정 기법
- 델파이 기법소
2. 상향식 비용 산정 기법(down-top)
- LOC(원시 코드 라인 수)기법
- 개발 단계별 인원수(Effort per Task) 기법
2-1. 수학적 산정 기법(경험적 추정 모형, 실험적 추정 모형)
- COCOMO(Constructive COst MOdel)
- Putman 모형
- 기능 점수(FP) 모형
3. 자동화 추정 도구
- SLIM
- ESTIMACE
소프트웨어 3R
1. 3R
- 레포지토리(Repository)를 기반으로 역공학(Reverse Engineering), 재공학(Reengineering), 재사용(Reuse)을 통해 소프트웨어 생산성을 극대화하는 기법
1) 소프트웨어 3R의 추진 배경
- 소프트웨어 위기 극복
- 소프트웨어 개발 생산성 향상
- 유지보수 비용의 절감
- 소프트웨어 변경 요구사항의 신속한 대처
2) 소프트웨어 3R의 구성

- 요구분석, 설계, 구현의 순서로 소프트웨어를 개발하는 것을 순공학이라고 하며, 그 반대로 이미 개발된 소프트웨어를 분석하는 것을 역공학이라고 함
- 역공학을 통해 기존의 설계를 복구한 결과를 재구조화를 통해 재공학 과정을 거친 후 만들어진 S/W의 단위들로 재사용을 함
3) 3R 관련 개념
| 접근방법 | 주요 내용 |
| 순공학 | 추상개념의 현실화, 요구분석 -> 설계 -> 구현 |
| 재구조화 | 기능 변경 없이 소스코드의 재편성(표현의 변형) |
| 순환공학 | 순공학 후에 다시 역공학을 하는 과정 |
| 동기 순환공학 | 순환공학 시에 설계와 코딩을 동시에 변환하는 과정 |
| 비동기 순환공학 | 순환공학 시에 설계와 코딩을 따로 변환하는 과정 |
4) 3R 구성요소
| 접근방법 | 주요 내용 |
| 역공학(Reverse Engineering) | 자동화된 도구의 도움으로 물리적 수준의 소프트웨어 정보를 논리적인 소프트웨어 정보의 서술로 추출하는 프로세스 |
| 재공학(Re-engineering) | 자동화된 도구를 현존하는 시스템을 점검 또는 수정하는 프로세스 |
| 재사용(Reuse) | 이미 개발되어 그 기능, 성능 및 품질을 인정받았던 소프트웨어의 전체 또는 일부분을 다시 사용 |
2. 역공학
1) 역공학의 정의
- 자동화된 도구(CASE)의 도움으로 물리적 수순의 소프트웨어 정보를 논리적인 소프트웨어 정보의 서술로 추출하는 프로세스
2) 역공학의 장점
- 재문서화를 통하여 현존하는 시스템의 지식을 재 회득함.
- 현존 시스템의 데이터와 논리에 효율적인 분석을 통하여 유지보수를 신속히 수행
- 현존하는 시스템의 정보를 Repository에 펼칠 수 있음
- 시스템 개발과 유지보수를 자동화
- 현존 시스템 설계를 재사용함
- 구현 독립적인 논리적인 레벨에서 작업함
3) 소프트웨어 역공학의 종류
- 논리 역공학 : 원시코드로부터 정보를 뽑아내 물리적이고 논리적인 설계정보를 획득하는 Repository를 정의함, (원시코드 à 정보추출 à 물리적 설계정보)
- 자료 역공학 : 물리적인 데이터 서술로부터 개념적, 논리적인 정보를 추출, 기존 파일시스템에서 데이터베이스의 전이 또는 기존 데이터 베이스에서 신규 데이터베이스로 전이 수행
4) 역공학에 사용되는 입력유형과 그에 따른 출력유형
| Input | Output |
| - 원시코드, 목적코드, 작업 제어 절차 - 라이브러리, 디스크 디렉토리 - 텍스트 자료, 데이터베이스 구조 - 입출력 형태와 자료, 각종 문서 |
- 구조도 - 자료사전 - 자료 흐름도 - 제어 흐름 그래프 - 객체 관계도 - 자료 흐름 그래프 |
5) 소프트웨어 역공학 프로세스
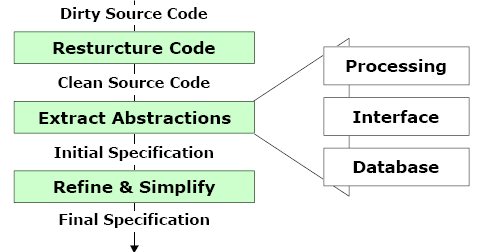
3. 소프트웨어 재공학(Reengineering)
1) 재공학(Reengineering)의 정의
- 자동화된 도구로 현전하는 시스템을 점검 또는 수정하는 프로세스
- 시스템의 재설계, 교체를 CASE 도구가 사용하도록 순공학을 준비하는 과정
2) 소프트웨어 재공학의 목적
- 현재 시스템의 유지보수 향상
- 시스템의 이해와 변형을 용이하게 하며, 유지보수비용 및 시간 절감
- 표준 준수
- CASE의 사용 용이
3) 재공학의 단계
| 구분 | 설 명 |
| 원시코드로부터의 정보 추출 단계 |
원시코드나 데이터베이스 정보 등에서 필요한 정보들을 정보저장소에 저장 |
| 역 공학 단계 | 정보저장소에 있는 정보들로부터 새로운 정보를 인식하여 그들의 성질과 선택 사항들 결정 |
| 시스템의 향상과 검증단계 | 시스템 분석가가 정보구조, 정보흐름과 같은 응용분야에 대한 명세 단계의 정의를 향상 |
| 순 공학 단계 | 파일과 데이터베이스 설계, 프로그램 명세를 이용하여 최적화 설계로 기능을 향상 |
| 설계와 최적화 단계 | 파일과 데이터베이스 설계, 프로그램 명세를 이용하여 최적화 설계로 기능을 향상 |
| 원시코드의 생성 단계 | 정보저장소로부터 구현단계의 설계 내역을 바탕으로 원시코드를 생성 |
4) 재공학 적용기법의 종류 및 특징
| 구분 | 설 명 |
| 재구조화 | 소프트웨어 부품을 라이브러리에 모아놓고 새로운 소프트웨어 개발에 필요한 부품을 찾아내어 결합하는 방법 |
| 재모듈화 | 시스템의 모듈 구조를 변화시키는 것으로 시스템 구성요소의 클러스터 분석 및 결합도와 관련(결합도, 응집도) |
| 의미론적 정보추출 | 코드수준이 아닌 문서 수준이 설계 재공학 기법 |
4.소프트웨어 재사용(Reuse)
1) 소프트웨어 재사용(Reuse)의 정의
- 이미 개발되어 그 기능, 성능 및 품질을 인정 받았던 소프트웨어의 전체 또는 일부분을 다시 사용
- 새롭게 개발되는 소프트웨어의 품질과 생산성 및 신뢰성을 높이고 개발기간과 비용을 감소시켜 소프트웨어 위기 극복
2) 소프트웨어 재사용의 필요성
- 소프트웨어 생산의 TCO (Total Cost Overhead) 절감
- 높은 품질의 소프트웨어 생산을 위한 공유 및 활용 효과
3) 소프트웨어 재사용의 기본원칙
- 범용성
- 모듈성
- 하드웨어 독립성
- 소프트웨어 독립성
- 자기 문서화
4) 소프트웨어 재사용의 목표
| 목표 | 설 명 |
| Reliability | 신뢰성 향상 (기능, 안정, 속도 등의 사전 성능 검증됨) |
| Extensibility | 확장성 향상 (검증된 기능 기반으로 Upgrade 용이함) |
| Productivity | 생산성 향상 (비용,시간,위험 등 전체적 개발 프로세스 향상됨) |
| Usability | 사용성 향상 (독립된 컴포넌트로써의 조립성 제공됨) |
| Maintainability | 유지보수성 (품질개선,오류수정,운영,Upgrade이 용이함) |
| Adaptability | 적응성 향상 (독립된 컴포넌트로써의 새로운 Process 적용에 용이함) |
5) 소프트웨어 재사용의 기술적 접근방법
| 기술적 접근방법 | 설 명 |
| 부품조립 방안 | 소프트웨어 부품들을 라이브러리에 모아놓고 새로운 소프트웨어 개발에 필요한 부품들을 찾아내어 결합시켜 나가는 방법 |
| 모형화 방안 | 소프트웨어에 대한 일반적인 모형을 만들어 놓고 거기에 필요한 매개변수를 적용하여 필요에 따라 소프트웨어를 생성해 내는 방법 |
| 기존 소프트웨어 수정방안 | 기존의 소프트웨어를 새로운 소프트웨어로 발전 시킬 수 있도록 하며 전체 소프트웨어를 먼저 정립한 후 새로운 모듈을 개발하고 기존의 모듈을 수정, 삭제하면서 단계적으로 개선 시켜 나감 |
6) 소프트웨어 재사용 활용 및 구현 기법
가. 활용 기법 종류
| 기법 종류 | 내용 |
| Copy | 소프트웨어 코드를 Copy하여 목적에 맞게 수정하여 사용하는 방법 |
| Pre-Processing | Include 함수를 사용하여 Compile시에 포함되도록 하는 방법 |
| Library |
Sub Program 집합인 Library를 활용해 Link시에 포함되도록 하는 방법 |
| Package | Global Variable, Package Interface를 통한 정적인 활용 방법 |
| Object |
Global Variable, Object Interface를 통한 실행중의 동적인 활용방법 |
| Generics | Object의 다형성을 이용하는 방법 |
| 객체 지향 | 객체 지향 방법의 상속성, 다형성 등의 성질을 활용하는 방법 |
| Component | 컴포넌트의 독립성, 조립성, 표준성 등을 활용하는 방법 |
나. 구현기법 종류
| 기법 | 특 징 |
| Classification | -코드, 객체, 변수 등의 속성에 대해 표준 Pool활용 -Code Generation, Variable Standardization -소프트웨어 생산의 TCO(Total Cost Overhead)절감 |
| Design Pattern | -특정 도메인에 대한 시스템 개발 경험자의 설계 및 구현의 결과를 재활용 - Business Process, 공통함수/언어 등 |
| Modulation | -시스템 분해, 추상화 등으로 Debugging, Test Integration, Modification을 수행 -Loosely Coupled, Tightly cohesion추구 |
| OOD | -상속성, 추상성, 다양성, 동적바인딩 등의 활용 -Class, 4GL에서의 Component |
| CBD | -ITA/EA기반의 Component활용 -분산객체 (DCOM, EJB, CORBA)등 |
fan-in / fan-out / width / depth
1.fan-in
어떤 모듈을 제어(호출)하는 모듈의 수
하나의 모듈이 제어받는 상위 모듈의 수
게이트가 수용할 수 있는 최대 입력의 수
2. fan-out
어떤 모듈어 의해 제어(호출)되는 모듈의 수
하나의 모듈이 제어하는 하위 모듈의 수
출력 단자에 접속하여 신호를 추출할 수 있는 최대 허용 출력 수
시스템 복잡도 최적화를 위해서는 팬인은 높게, 팬아웃은 낮게 설계해야 한다.
3. width
제어의 전체 폭
4. depth
제어 단계의 수
배열과 리스트
1. 배열 (Array)
▶ 특징
- 같은 타입의 데이터를 나열한 선형 자료구조(sequence container)다.
- 배열의 크기는 선언 시점에 정해져야 한다.
- 생성 시 stack에 메모리가 할당된다.
▶ 시간 복잡도
- 삽입/삭제
- 배열의 맨 앞에 삽입/삭제하는 경우 : O(n)
- 배열의 맨 뒤에 삽입/삭제하는 경우 : O(1)
- 배열의 중간에 삽입/삭제하는 경우 : O(n)
- 탐색 (인덱스 접근) : O(1)
▶ 장점
- 인덱스 접근 가능 : 인덱스를 통해 임의의 원소에 접근(random access)이 가능하다. 자료구조의 크기가 클수록 더 강력한 장점이 된다.
- 연속된 메모리에 할당 : 주소값으로 원소에 접근할 수 있어서 관리가 편하다.
▶ 단점
- 삽입과 삭제가 어렵고 오래 걸림 : 원소를 삽입하거나 삭제할 경우, 해당 원소 이후의 모든 원소들을 한칸씩 밀거나 당겨야 한다. (연속된 메모리에 저장되기 때문)
- 배열의 크기는 고정적 : 배열의 크기를 변경하기 위해서는 원하는 크기의 새로운 배열을 선언한 뒤 기존 원소들을 복사해야 한다.
- 공간 낭비 발생 가능 : 연속된 메모리를 사용하기 때문에 중간에 데이터가 삭제되면 공간 낭비가 발생할 수 있다. ex. 처음에 배열 크기를 100으로 생성했는데 10정도 밖에 쓰지 않으면 나머지 공간은 빈 공간으로 낭비가 발생한다.
- 메모리를 많이 사용 : 연속적인 메모리 할당이 필요하기 때문이다.
▶ 언제 사용할까
- 데이터 개수가 확실하게 정해져 있을 때
- 데이터의 삭제와 삽입이 적을 때
- 검색을 해야할 때
2. 리스트 (Linked list)
▶ 특징
- 데이터를 순차적으로 저장하는 선형 자료구조 (sequence container)
- 노드를 연결하여 만든 리스트
- 첫번째 노드를 헤드(head), 마지막 노드를 테일(tail)이라고 한다.
- 각 노드는 데이터와 다음 노드를 가리키는 포인터로 구성된다.
- 생성 시 heap에 메모리가 할당된다.
▶ 시간 복잡도
- 삽입
- 리스트의 맨 앞/뒤에 삽입하는 경우 : O(1)
- 리스트의 중간에 삽입하는 경우 : O(n) (탐색하는 시간)
- 삭제
- 리스트의 맨 앞/뒤에서 삭제하는 경우 : O(1)
- 리스트의 중간에서 삭제하는 경우 : O(n) (탐색하는 시간)
- 탐색 : O(n)
▶ 장점
- 삽입과 삭제가 용이 : 포인터로 연결되어 있어서 가리키는 노드만 변경해주면 됨
- 크기가 가변적 : 새로운 원소 추가 시 동적으로 크기가 변경된다.
- 불연속적 메모리 할당 : 빈 공간 없이 데이터를 저장할 수 있다. (ex. 중간 데이터 삭제 시)
- 사용한 메모리를 재사용할 수 있다
▶ 단점
- 인덱스 접근(ex. [], .at(i))이 불가능 : 반복자를 이용하여 탐색(sequential access)하기 때문에 속도가 느리다.
- 포인터로 인한 저장 공간의 낭비 : 다음 노드 가리키는 포인터를 저장하는 공간이 필요하다.
▶ 언제 사용할까
- 크기가 정해져 있지 않을 때
- 삽입과 삭제가 자주 일어날 때
- 검색을 자주 하지 않을 때
3. 리스트 ArrayList

ArrayList는 기본적으로 배열을 사용한다. 하지만 일반 배열과 차이점이 존재한다.
일반 배열은 처음에 메모리를 할당할 때 크기를 지정해주어야 하지만, ArrayList는 크기를 지정하지 않고 동적으로 값을 삽입하고 삭제할 수 있다.
조회
ArrayList는 각 데이터의 index를 가지고 있고 무작위 접근이 가능하기 때문에, 해당 index의 데이터를 한번에 가져올 수 있다.
데이터 삽입과 삭제
데이터의 삽입과 삭제시 ArrayList는 그만큼 위치를 맞춰주어야 한다.
위의 사진으로 예를들면 5개의 데이터가 있을 때 맨 앞의 2를 삭제했다면 나머지 뒤의 4개를 앞으로 한칸씩 이동해야 한다.
삽입과 삭제가 많다면 ArrayList는 비효율적이다.
출처: https://dev-coco.tistory.com/19
http://www.jidum.com/jidums/view.do?jidumId=302
https://m.blog.naver.com/ionebabo/221654102886
출처: https://y-oni.tistory.com/25 [욘블로그(Yon-Blog)]
'전공 > 그 외' 카테고리의 다른 글
| [알고리즘] 전공 필기 시험 준비2 (0) | 2022.04.01 |
|---|---|
| [자료구조] 전공 필기 시험 정리 (0) | 2022.04.01 |
| [알고리즘] 전공 필기시험 정리 (0) | 2022.04.01 |
| [소프트웨어공학] 전공 필기 시험 정리 (0) | 2022.03.31 |
| [컴퓨터 구조] 전공 필기 시험 정리 (0) | 2022.03.31 |



