1. 정규화(Normalized)란?
- 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스
- 정규화(Normalization)의 목표는 테이블 간 중복 데이터를 허용하지 않는 것이다. 중복된 데이터를 허용하지 않음으로써 무결성(Integrity)를 유지할 수 있으며, DB의 저장 용량 역시 줄일 수 있다.
2. 정규화의 장단점
1) 장점
- 데이터베이스 변경 시 이상 현상(Anomaly) 제거
- 저장 공간의 최소화
- 데이터 구조의 안정성 및 무결성 유지
- 데이터 삽입 시 릴레이션 재구성의 필요성 감소
- 효과적인 검색 알고리즘 생성 가능
2) 단점
- 릴레이션 간의 JOIN 연산 증가→ 질의에 대한 응답 시간 저하
3. 정규화를 하는 이유
- 이상 문제를 해결하기 위해
- 테이블 간 중복 데이터를 허용하지 않고 DB 용량을 줄이기 위해
- 데이터 저장을 논리적으로 하기 위해
* 정규화의 원칙
1. 정보의 무손실 : 분해된 릴레이션이 표현하는 정보는 분해되기 전의 정보를 모두 포함해야 한다.
2. 최소 데이터 중복 : 이상 현상을 제거, 데이터 중복을 최소화해야 한다.
3. 분리의 원칙 : 하나의 독립된 관계성은 하나의 독립된 릴레이션으로 분리해서 표현해야 한다.
4. 정규화 대상
온라인 거래 시스템 같은 OLTP(OnLine Transaction Processing) 데이터베이스는 CRUD(Create, Read, Update, Delete) 가 많이 일어나기 때문에 정규화 되는것이 좋지만, 분석 리포트 같은 OLAP(OnLine Analytical Processing) 데이터베이스는 분석과 리포팅을 위해 사용되기 때문에 연산의 속도를 위해 반정규화(denormalization)의 대상이 된다.
5. 비정규화 / 반정규화
- 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로, 의도적으로 정규화 원칙을 위배하는 행위
- 어느 정도의 데이터 중복이나 그로 인해 발생하는 데이터 갱신 비용은 감수하는 대신 조인 횟수를 줄여 한층 효율적인 쿼리를 날릴 수 있도록 하겠다는 것
- 일반적으로 join을 많이 사용해야 할 경우, 대량의 범위를 자주 처리하는 경우 등 조회에 대한 처리가 중요하다고 판단될 때 부분적으로 반정규화를 한다.
1) 장점
- 빠른 데이터 조회
- 살펴볼 테이블이 줄어들기 때문에 데이터 조회 쿼리가 간단해짐
2) 단점
- 데이터 갱신이나 삽입 비용이 높음
- 데이터 갱신 또는 삽입 코드를 작성하기 어려워짐
- 데이터 간 일관성이 깨질 수 있음
- 데이터를 중복하여 저장하므로 더 많은 저장 공간이 필요
3) 비정규화 대상
- 자주 사용되는 테이블에 액세스하는 프로세스의 수가 가장 많고, 항상 일정한 범위만을 조회하는 경우
- 테이블에 대량 데이터가 있고 대량의 범위를 자주 처리하는 경우, 성능 상 이슈가 있을 경우
- 테이블에 지나치게 조인을 많이 사용하게 되어 데이터를 조회하는 것이 기술적으로 어려울 경우
4) 종류
릴레이션 역정규화
릴레이션 병합
: 두 릴레이션 간의 빈번한 참조로 성능이 저하되는 문제를 해결하기 위해 병합
릴레이션 분할
: 데이터를 검색할 때, 릴레이션의 데이터 목록을 순차적으로 검색하게 되어 자주 사용하지 않는 속성이나 튜플이 있을 경우 성능을 저하시키므로 자주 사용하는 속성이나 튜플을 분해
- 수직 분할 : 자주 사용하는 속성과 그렇지 않은 속성을 구분해서 분할하는 방법
- 수평 분할 : 자주 사용하는 튜플과 그렇지 않은 튜플을 구분해서 분할하는 방법
속성 역정규화 : 릴레이션의 성능을 향상하기 위해 속성 또는 파생 속성을 추가
파생 속성(Delivered Attribute): 현재 릴레이션에 없지만 작업의 효율을 위해 계산을 통해 추가한 속성
->정리하면, 정규화 데이터베이스(normalized database)는 중복을 최소화하도록 설계된 데이터베이스를 말하고
비정규화 데이터베이스(denormalized database)는 읽는 시간을 최적화하도록 설계된 데이터베이스를 말한다.
6. 함수적 종속성
함수적 종속이란, 데이터들이 어떤 기준값에 의해 종속되는 것을 의미한다.
이론적으로 정규화를 수행하려면 속성들간의 관련성을 파악해야 하는데, 어떤 테이블의 속성 A와 B에 대하여 A값에 의해 B값이 유일하게 정해지는 관계를 말하며, "B는 A에 함수 종속이다"라고 한다. A→B의 기호로 나타낸다.
이때, A를 결정자(Determinant)라고 하고, B를 종속자(Dependant)라고 한다.
1) 완전함수 종속성(fully functional dependency) : 어떤 속성이 기본키에 대해 완전히 종속적인 경우
- X’⊂X 이고 X’→Y 를 만족하는 애트리뷰트 X'이 존재하지않음

- <수강> 릴레이션이 (학번, 이름, 학년, 과목번호, 성적)으로 되어 있고 (학번, 과목번호)이 기본키인 경우
- {학번, 과목번호} → 성적
- 완전 함수적 종속성은 이미 정규화가 되어 있기에 정규화 대상이 아님
2) 부분함수 종속성(partial functional dependency, 2NF) : 기본키를 구성하는 속성의 일부에 종속되거나, 기본키가 아닌 다른 속성에 종속되는 경우
- '학년'이나 '이름'은 '과목명'에 관계없이 '학번'이 같으면 항상 같은 '학년' / '이름'을 도출 → 즉, 기본키의 일부인 '학번'에 의해서 '학년'이 결정되므로 '학년'과 '이름'은 부분 함수적 종속
- 부분 함수적 종속성은 2차 정규화 대상
3) 이행함수 종속성(transitive dependence, 3NF) : A, B, C 세 속성이 있고 A→B, B→C 종속 관계가 있을 때, A→C가 성립하는 경우
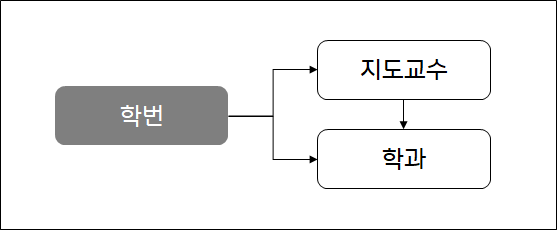
- 학번 → 지도교수, 지도교수 → 학과, 따라서 학번 → 학과
- 3차 정규화 대상
4) 결정자함수적 종속성(boyce-codd normalization, BCNF) :
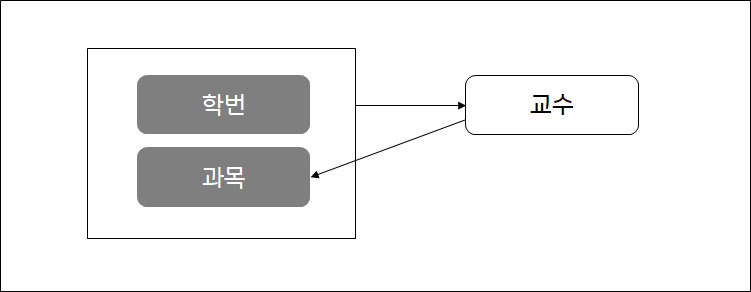
- 함수적 종속성이 되는 결정자가 후보키가 아닌 경우 (X→Y에서 X가 후보키가 아님)
- 교수 → 과목
- Boyce/Codd 정규화 대상
6-2) 함수 종속의 추론규칙(Armstrong's axioms, 암스트롱의 공리)
반사의 공리(Reflective)
- Y가 X의 부분 집합이면, X → Y이다.
확대의 공리(Augmentation)
- X → Y이면, XZ → YZ이다.
이행의 공리(Transitivity)
- X → Y이고 Y → Z이면 X → Z이다.
합집합의 성질(Union)
- X → Y이고 X → Z이면 X → YZ이다.
분해의 성질(Decomposition)
- X → YZ이면 X → Y이고 X → Z이다.
유사 이행적 성질(Pseudo-Transivity)
- X → Y이고 YZ → W이면, XZ → W이다.
7. 이상 현상
릴레이션에서 일부 속성들의 종속이나 데이터의 중복으로 인해 데이터 조작시 불일일치가 발생하는 것
테이블을 설계할 때 잘못 설계하여 데이터를 삭제,수정,삽입할 때 논리적으로 오류가 생기는 것
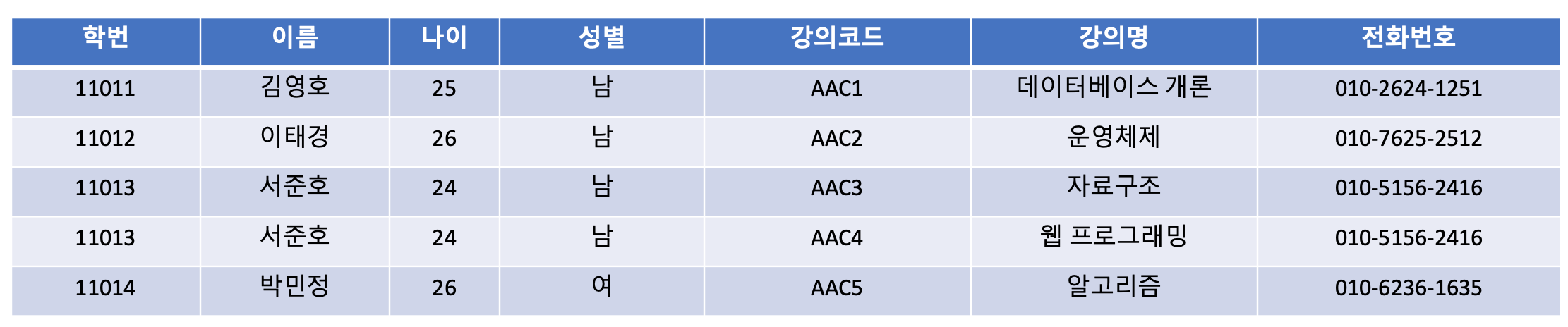
1. 삽입 이상 : 데이터를 저장할 때 원하지 않는 정보가 함께 삽입되는 경우
강의를 아직 수강하지 않은 신규 학생을 삽입할 경우 강의코드 속성에는 null값이 들어가야 하는 문제가 발생
2. 갱신 이상 : 중복된 튜플 중 일부의 속성만 갱신 시킴 으로써 정보의 모순성이 발생하는 경우
서준호 학생의 전화번호를 수정할 경우, 2개 튜플 모두 바꿔줘야 함. 하나라도 안바꿀 경우 한명의 학생에 대한 정보가 서로 달라지는 정보의 모순성이 발생
3. 삭제 이상 : 튜플을 삭제함으로써 유지되어야 하는 정보 까지도 연쇄적으로 삭제되는 경우
데이터베이스 개론 강의를 삭제하게 되면 김영호 학생의 데이터까지 삭제되는 문제가 발생
8. 정규형
정규화 : 이상현상이 발생하는 릴레이션을 분해하여 이상현상을 제거하는 과정을 의미한다.
정규형 : 정규화 된 정도를 정규형(Normal Form) 으로 표현하는데, 정규형에는 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, 6NF 까지 있다. 비공식적 표현으로는 3NF 가 되었으면 정규화 되었다고 말한다.

1) 제 1정규형(First Normal Form, 1NF)
- 테이블의 컬럼이 원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해한 형태
- 속성의 원자성(Atomic)을 확보, 기본키를 설정
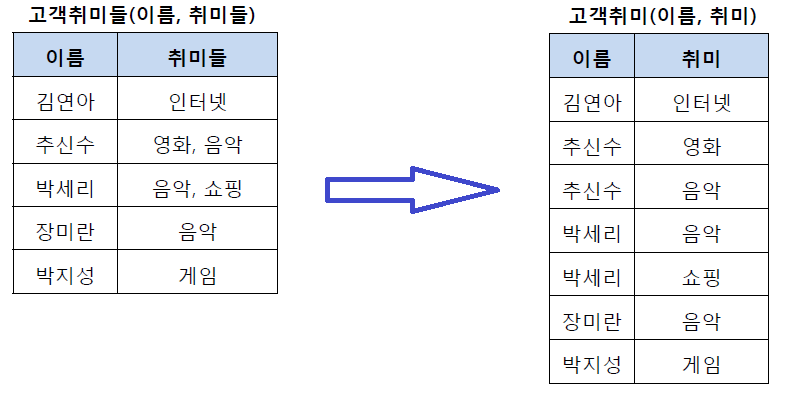
- 왼쪽 테이블 : 추신수와 박세리는 여러 개의 취미를 가지고 있기 때문에 제1 정규형 위배
- 오른쪽 테이블 : 제 1정규화를 만족
2) 제 2정규형(Second Normal Form, 2NF)
- 제 1 정규화를 만족해야 함
- 완전 함수 종속을 만족하도록 테이블을 분해한 형태
- 기본키가 2개 이상의 속성으로 이루어진 경우, 부분 함수 종속성 제거
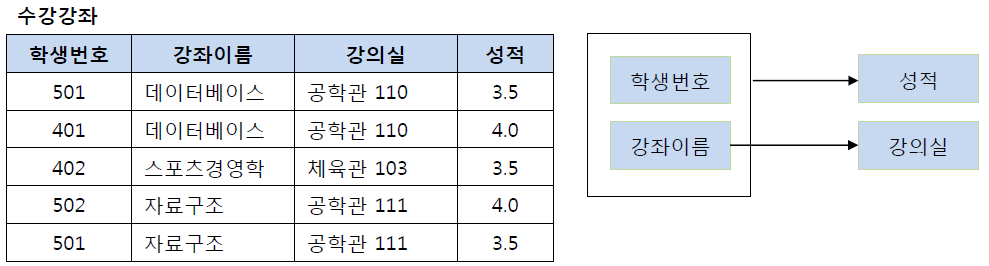
수강강좌 릴레이션에서 기본키는 (학생번호, 강좌이름)으로 복합키이며, (학생번호, 강좌이름) -> (성적) / (강의실) 을 만족
그런데 강의실은 강좌 이름에 의해서도 결정될 수 있기 때문에 부분 함수 종속성 발생. 제 2 정규형 위배
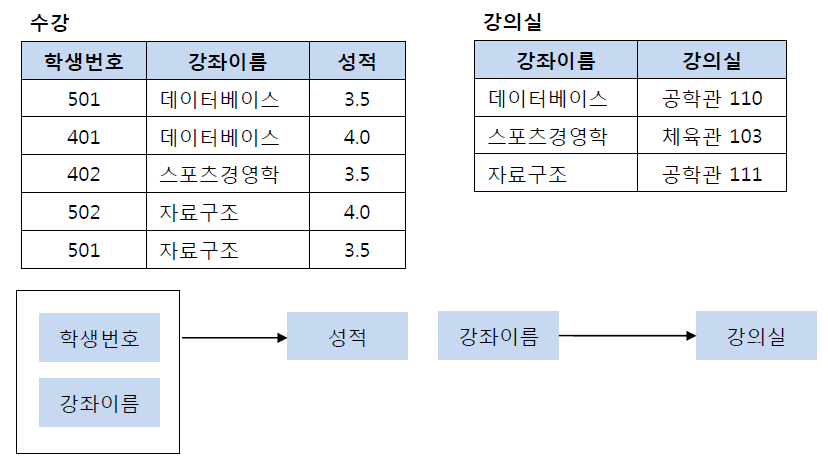
강의실 정보를 분해하여 별도의 테이블로 관리하여 제2 정규형을 만족
3) 제 3정규형(Third Normal Form, 3NF)
- 제 2 정규화를 만족해야 함
- 이행적 종속을 제거하도록 테이블을 분해한 형태
(이행적 종속 : A -> B, B -> C가 성립할 때 A -> C가 성립되는 것)
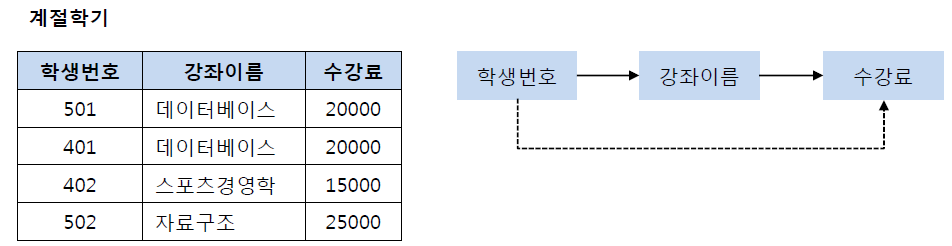
계절학기 릴레이션에서 생번호는 강좌이름과 수강료를 결정짓고, 강좌이름은 수강료를 결정짓는다. (학생번호) -> (강좌 이름) , (학생번호) -> (수강료) , (강좌 이름) -> (수강료) 관계를 가지므로 제3 정규형에 위배
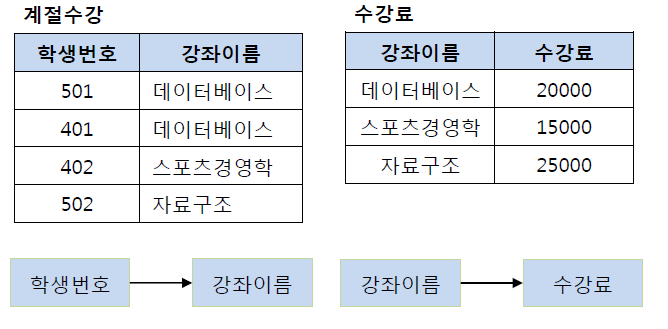
계절수강 릴레이션과 수강료 릴레이션으로 분해하여 제 3정규형 만족
이행적 종속을 제거하는 이유: 예를 들어 501번 학생이 수강하는 강좌가 스포츠경영학으로 변경되었을 때, 이행적 종속이 존재한다면 501번의 학생은 스포츠경영학이라는 수업을 20000원이라는 수강료로 듣게 된다. 강좌 이름에 맞게 수강료를 다시 변경할 수 있지만, 이러한 번거로움을 해결하기 위해 제3 정규화를 수행한다.
4) BCNF (Boyce and Codd Normal Form)
- 제 3 정규화를 만족해야 함
- 함수 종속성 A→B가 성립할 때 모든 결정자 A가 후보키가 되도록 테이블을 분해한 형태
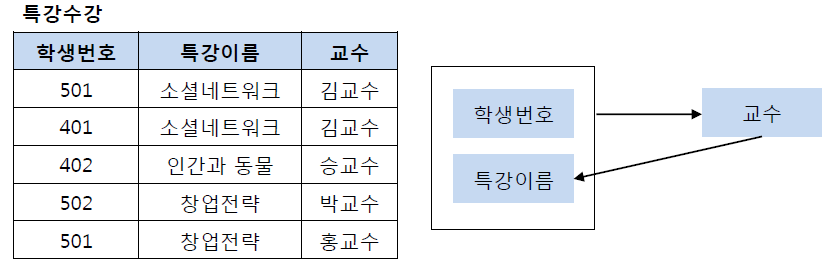
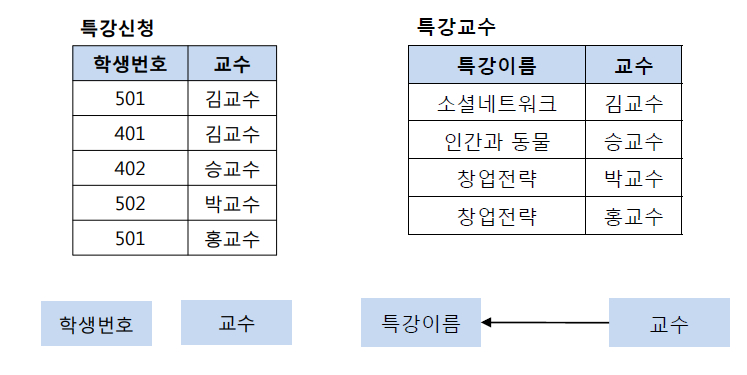
특강수강 릴레이션에서 기본키는 (학생번호, 특강이름)이다.
(학생번호, 특강이름)은 교수를 결정하고 있고, 교수는 특강이름을 결정하고 있다.
교수는 특강 이름을 결정하는 결정자이지만, 후보키가 아니기 때문에 BCNF 정규형에 위배
5) 제 4정규형 (Fourth Normal Form, 4NF )
- BNCF를 만족해야 함
- 다치 종속성을 제거하도록 분해한 형태
* 다치종속(multi-value dependent) : 릴레이션 내 두 어트리뷰트 집합 사이 성립하는 제약조건 중의 하나. 두개의 독립된 애트리뷰트가 1:N 관계로 대응하는 관계를 말하며 "->>"와 같이 표기한다.
즉, 릴레이션 R의 속성 X, Y, Z가 있을 때 (X, Y)에 대응하는 Z의 집합이 X값에만 종속되고, Y값에 무관하면 Z는 X에 다치종속이라 하고, X ->> Y로 표기한다.
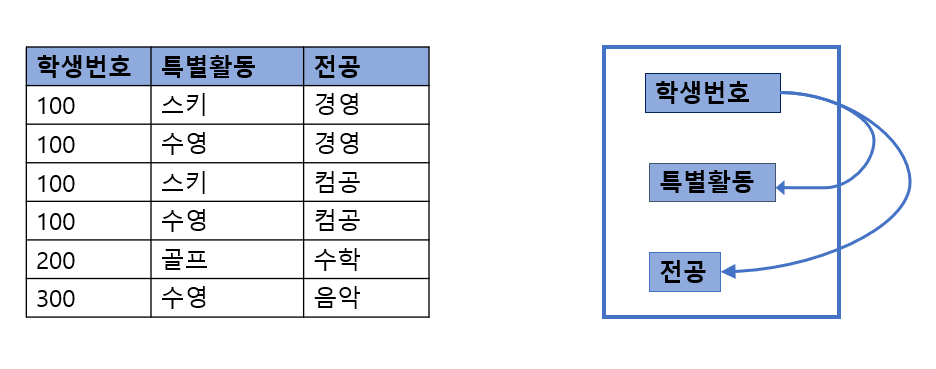
- 키 : 학생번호 + 특별활동 + 전공(복수 전공 포함)
- 다치종속 : 학생번호 ->> 특별활동, 학생번호 ->> 전공
특별활동은 학생번호와 연계된 사항이며, 전공 역시 학생번호와 연계된 사항이다. 특별활동과 전공 간에는 관련성이 없다.
테이블의 일관성을 유지하기 위해 학생번호마다 특별활동과 전공의 모든 가능한 조합들을 포함해야 하며, 이로 인해 특별활동과 전공이 여러개 중복될 수밖에 없다.
이러한 제약 조건은 학생 테이블에 대한 다치 종속으로 표현된다. 두개의 독립적인 1:N 관계인 학생번호:특별활동과 학생번호:전공이 같은 테이블에 존재할 때 다치 종속성이 발생한다.
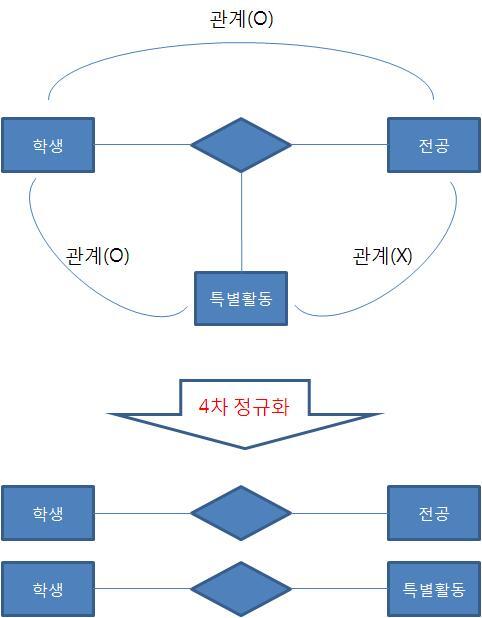
이런 현상이 발생하는 이유는 관계(relationship)이 제대로 파악되지 않았기 때문이다. 또한 어떤 학생이 어떤 특별활동과 어떤 전공을 하는 지에 2가지의 주제를 하나의 릴레이션에 포함했기 때문에 발생한 현상이다. 그림으로 표현하면 다음과 같다. 이러한 3원관계(3진관계)를 제거해야 한다.
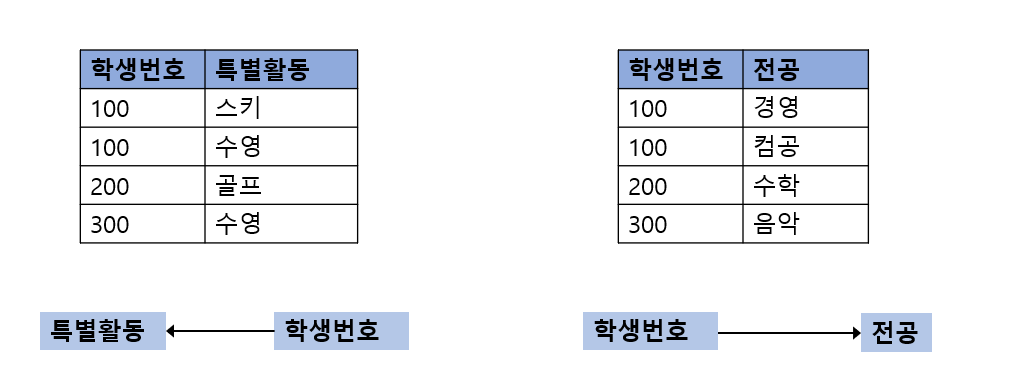
다음과 같이 특별활동 정보와 전공 테이블을 분해하여 제4 정규형을 만족한다.
6) 제 5정규형 (Fifth Normal Form, 5NF ) / PJ-NF(Projection-Join Normal Form)
- 제 4정규화를 만족해야 한다.
- 조인 종속성을 없앤 것이 제 5 정규형을 만족
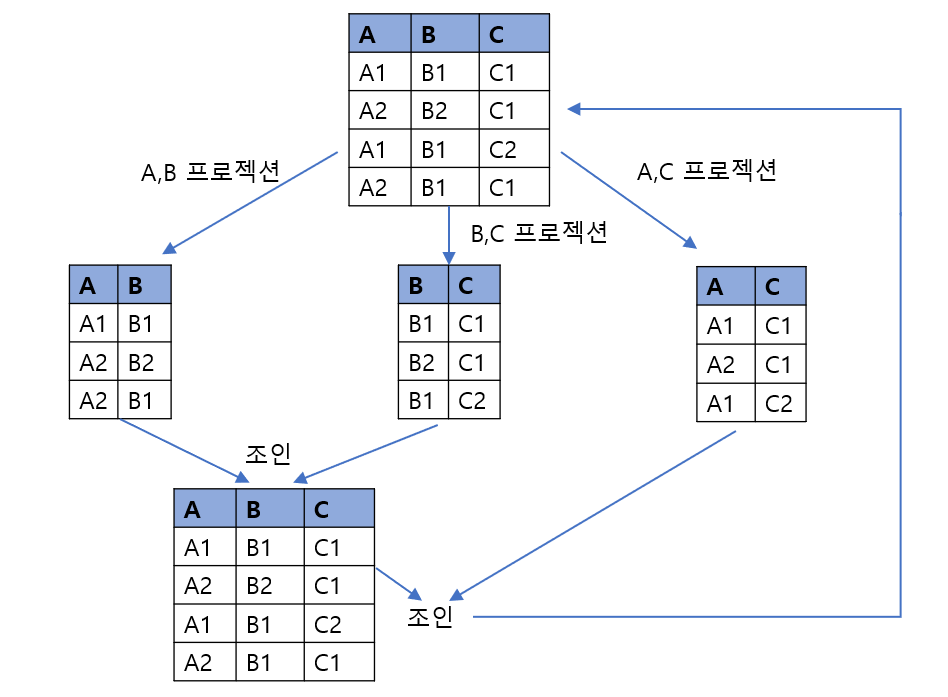
* 조인 종속(JD ; Join Dependency) : 하나의 릴레이션을 여러개의 릴레이션으로 분해하였다가, 다시 조인했을 때 데이터 손실이 없고 원래의 테이블과 동일하게 복원되는 제약조건
예를 들어 {A, B, C}를 릴레이션 R의 부분집합이라고 할 때, 릴레이션 R에서 {A, B, C}를 프로젝션한 것들을 조인한 것과 원래의 릴레이션 R이 같다면 릴레이션 R은 조인 종속(JD : Join Dependency)을 만족시킨 것
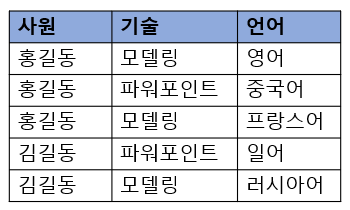
- 4정규형과 유사하지만 4정규형과 다른 점은 기술과 언어가 연관성이 있다.
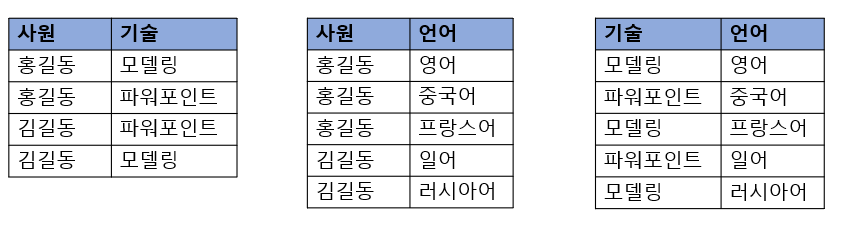
이렇게 세 개의 릴레이션으로 분해하고 나서 조인하면 다시 처음의 릴레이션으로 돌아갈 수 있으므로, 분해 전 릴레이션은 조인 종속이 존재하는 릴레이션이며 5정규형을 위반한 릴레이션
세 개의 릴레이션 중에서 어느 두 개의 릴레이션만 조인해서는 원래 데이터를 만들 수 없고 반드시 세 개의 릴레이션을 조인해야 원하는 요건을 얻을 수 있음 => 5정규형은 조인 종속이 존재하지 않아야 하므로 이와 같이 분해하면 더 이상 분해할 수 없는 5정규형이 됨
https://mangkyu.tistory.com/110
https://kosaf04pyh.tistory.com/294
https://wkdtjsgur100.github.io/database-normalization/
https://needjarvis.tistory.com/610
http://databaser.net/moniwiki/wiki.php/%EC%A0%95%EA%B7%9C%ED%99%94%EC%A0%95%EB%A6%AC
'전공 > DB' 카테고리의 다른 글
| MySQL튜닝3) 실행계획 살펴보기1 (0) | 2022.01.19 |
|---|---|
| MySQL튜닝2) SQL 튜닝 용어 이해하기2 (0) | 2022.01.12 |
| MySQL튜닝1) SQL 튜닝 용어 이해하기 (0) | 2022.01.05 |
| [DB 기술면접 질문 리스트] : JOIN (0) | 2021.10.17 |
| [DB 기술면접 질문 리스트] : 인덱스 (2) | 2021.10.14 |


